- Forward Future Daily
- Posts
- 👾 o3-Mini: A Turning Point in AI Development
👾 o3-Mini: A Turning Point in AI Development
Small, Fast, and Powerful: How o3-Mini Redefines AI Efficiency and Performance
Kim Isenberg
February 02, 2025
OpenAI has released o3-mini, a model that was announced in December and is now available in two versions: ‘Low’ and ‘High.’ The ‘High’ variant is only slightly more expensive than o1-Small but clearly outperforms Full-o1 in most benchmarks. This marks a turning point—one we’ll remember as the start of a new chapter. In this article, I will explain why the release of o3 and o3-mini is a milestone in AI history
What makes o3-mini so important?
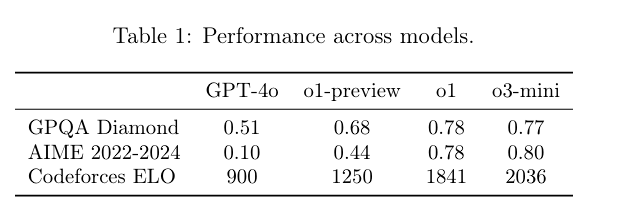
o3-mini is a smaller language model, but it offers such strong performance that it outperforms even OpenAI's best reasoning model to date, full o1 on most benchmarks (with the exception of o1-Pro). But not only the performance is remarkable - the costs are too. In the Codeforce benchmark, o3-mini achieves almost 200 points more Elo than o1, at almost the same cost as o1-mini. That is breathtaking.
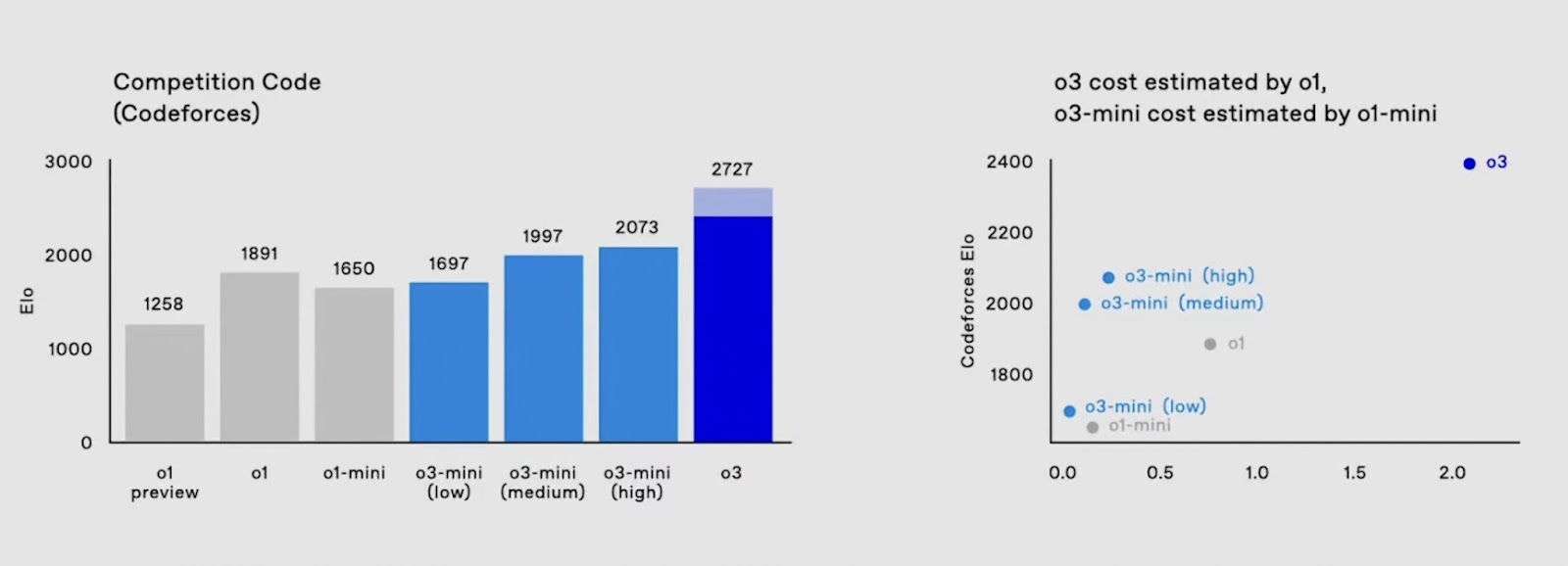
The development of o3 allows several conclusions to be drawn: we are not only seeing regular improvements to the models, but also a reduction in their size and cost. Some joke that AGI will one day run on a smart fridge. Given current trends, that idea is no longer far-fetched. We are increasingly seeing small language models that are significantly more powerful than state-of-the-art LLMs just a few months ago - and so efficient that they can be operated “on the edge” without any problems. Models with 1.5 billion parameters that run on a smartphone and are sufficient for everyday use. This is exactly where o3-mini comes in: It shows how good small (reasoning) models have become and how rapidly development is progressing.
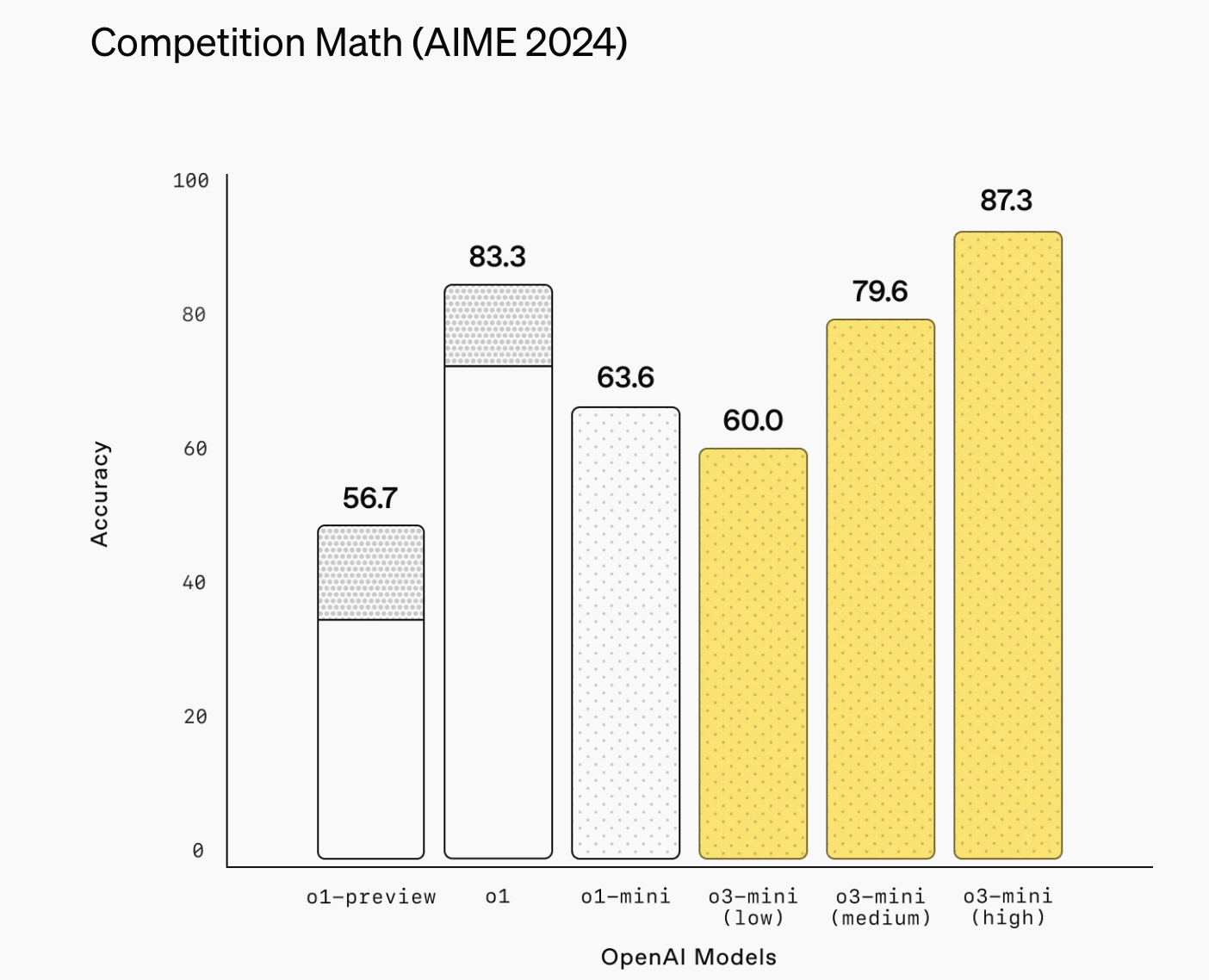
Jevons paradox and the revolution of small models
The combination of performance and low costs is a necessary strategic development for OpenAI. Recently, Jevons paradox was on everyone's lips after the release of DeepSeek R1 caused the share prices of major chip manufacturers to plummet. As a reminder, DeepSeek R1 was only a side project of the Chinese hedge fund “High-flyer”, whose training costs amounted to only 5.6 million US dollars.
Whether these figures are really correct remains to be seen. But one thing is clear: DeepSeek proved that outstanding AI reasoning models do not necessarily need access to the best chips such as H100 or B200 - a shock for the semiconductor industry. The assumption that the AI boom would drive up chip demand was called into question. NVIDIA lost around 20 percent of its market valuation in mere days.
Microsoft CEO Satya Nadella spoke out in this debate and reminded us of Jevons paradox. This states that increases in efficiency often do not lead to lower, but paradoxically to higher overall consumption. Why? Because the lower costs make the use of the product more economical and its application expands massively as a result.
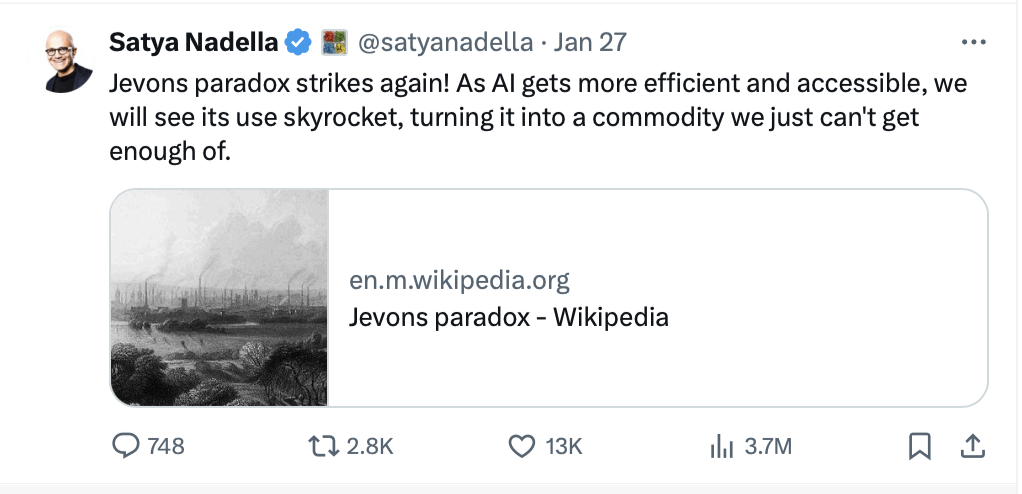
This is where o3-mini changes the game: by drastically reducing costs and resource consumption compared to Full-o1, its adoption will scale exponentially. This in turn means increasing compute requirements and presumably also higher revenues for OpenAI due to increased use via API. o3-mini is therefore a sharp but necessary response to the huge success of DeepSeek R1, which can even be run locally with sufficient computing power.
What makes this moment so significant is the fact that six months ago it would have been unthinkable to have a small language model that outperforms the best to date reasoning model while being as cheap as the smallest reasoning model (o1-mini). Just a few months ago, rumors were circulating about the Strawberry model, and hardly anyone could have predicted the incredible performance of the newly developed o3-mini just six months later—especially at such a low cost. Within a few months, the capacities of the models have virtually exploded - while their size continues to shrink.
The revolution of small models has begun - and it will fundamentally change the AI landscape in the coming years.
“Previewed in December 2024, this powerful and fast model advances the boundaries of what small models can achieve, delivering exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.” (OpenAI)
o3-mini is just the beginning
When we talk about o3-mini, we must always bear in mind the development time of modern reasoning models. It was only four months ago that OpenAI made o1-preview available for general use. On September 12, the preview version gave us a taste of the power of reasoning models. Especially in areas of logic, math and coding, where models can clearly validate correct results, o1-preview reached top positions in benchmarks. Shortly afterwards, full-o1 was released and achieved outstanding results in more difficult and complicated benchmarks using the new paradigm test-time compute.
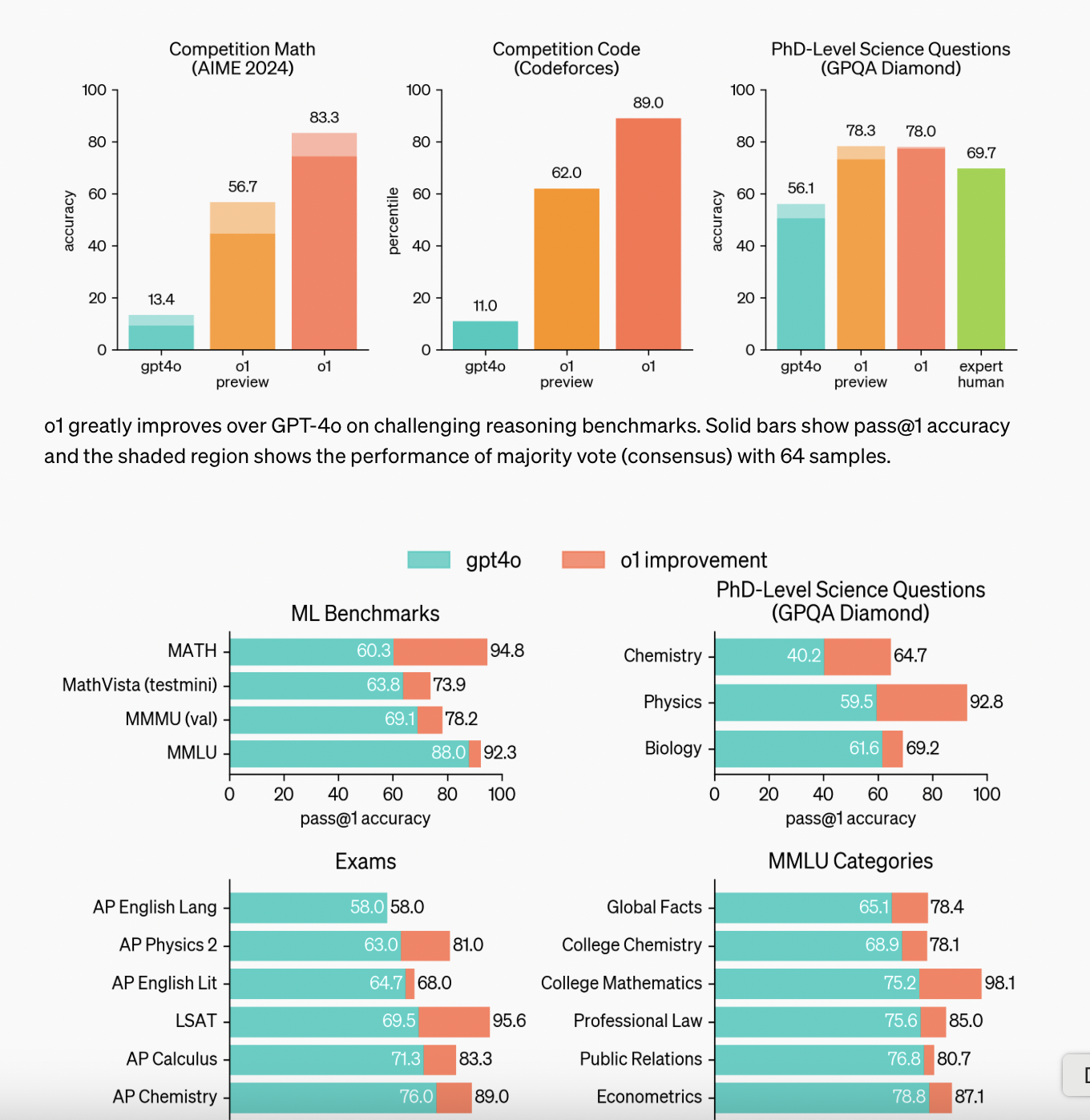
The world was shocked and excited at the same time. Inference scaling became the dominant paradigm; pre-training hit its limits, while the new scaling law unlocked unprecedented possibilities. More and more AI companies are turning to TTC and 2024 will go down in history as the year of the reasoners.
In December, however, OpenAI shocked the world once again. Just three months after the release of o1, we got a taste of the potential that lies in the new inference-scaling law. In just three months, the o3 model has undergone significant development, achieving a substantial performance improvement over o1. Notably, it achieved a 75.7% score on the ARC-AGI benchmark, underscoring its rapid advancement in a short period.
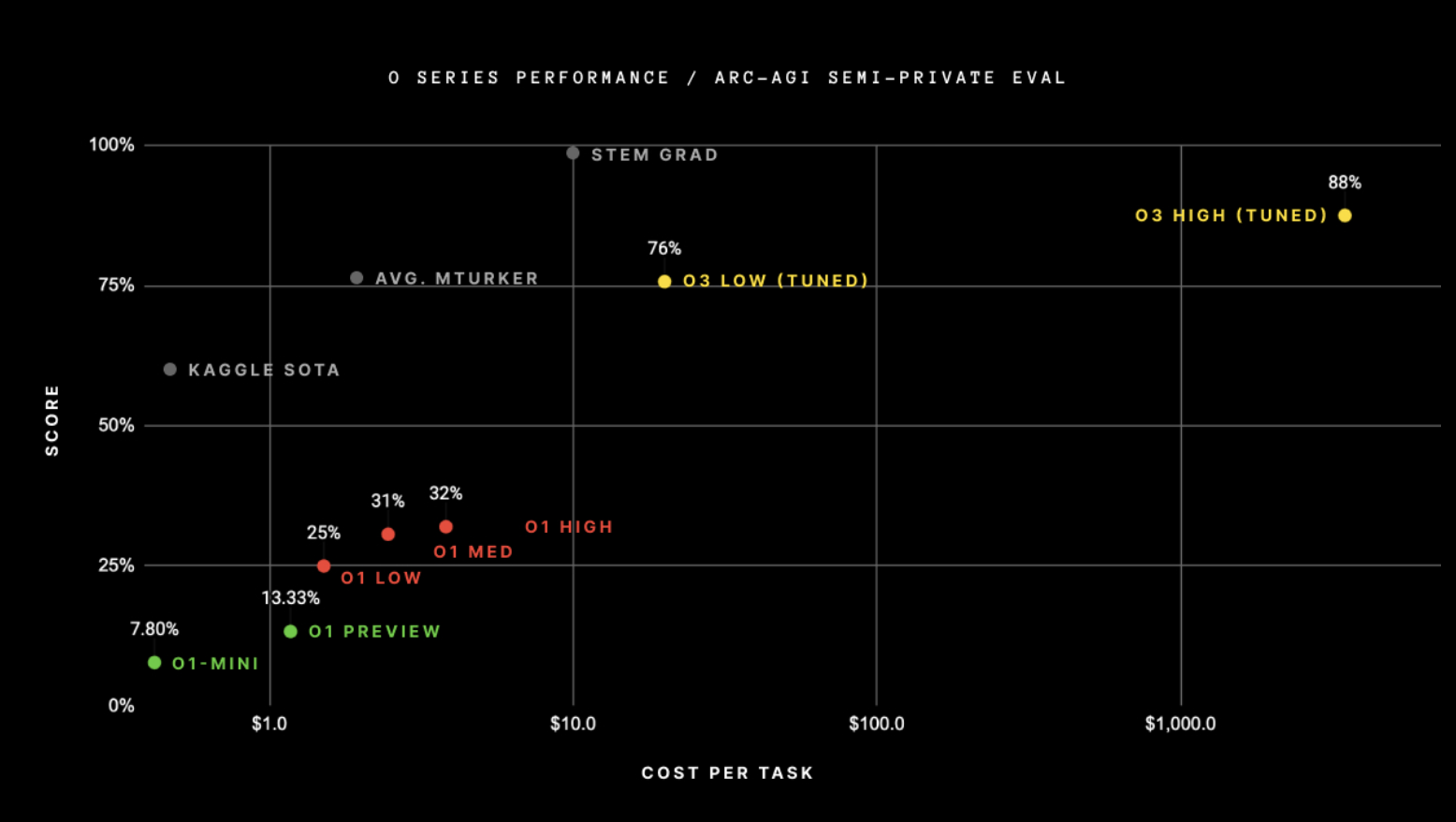
While o1-preview achieved 13.33% in the benchmark, o1 managed 32% when scaled up. o3, however, achieved an outstanding 88% when scaled to high-usage!
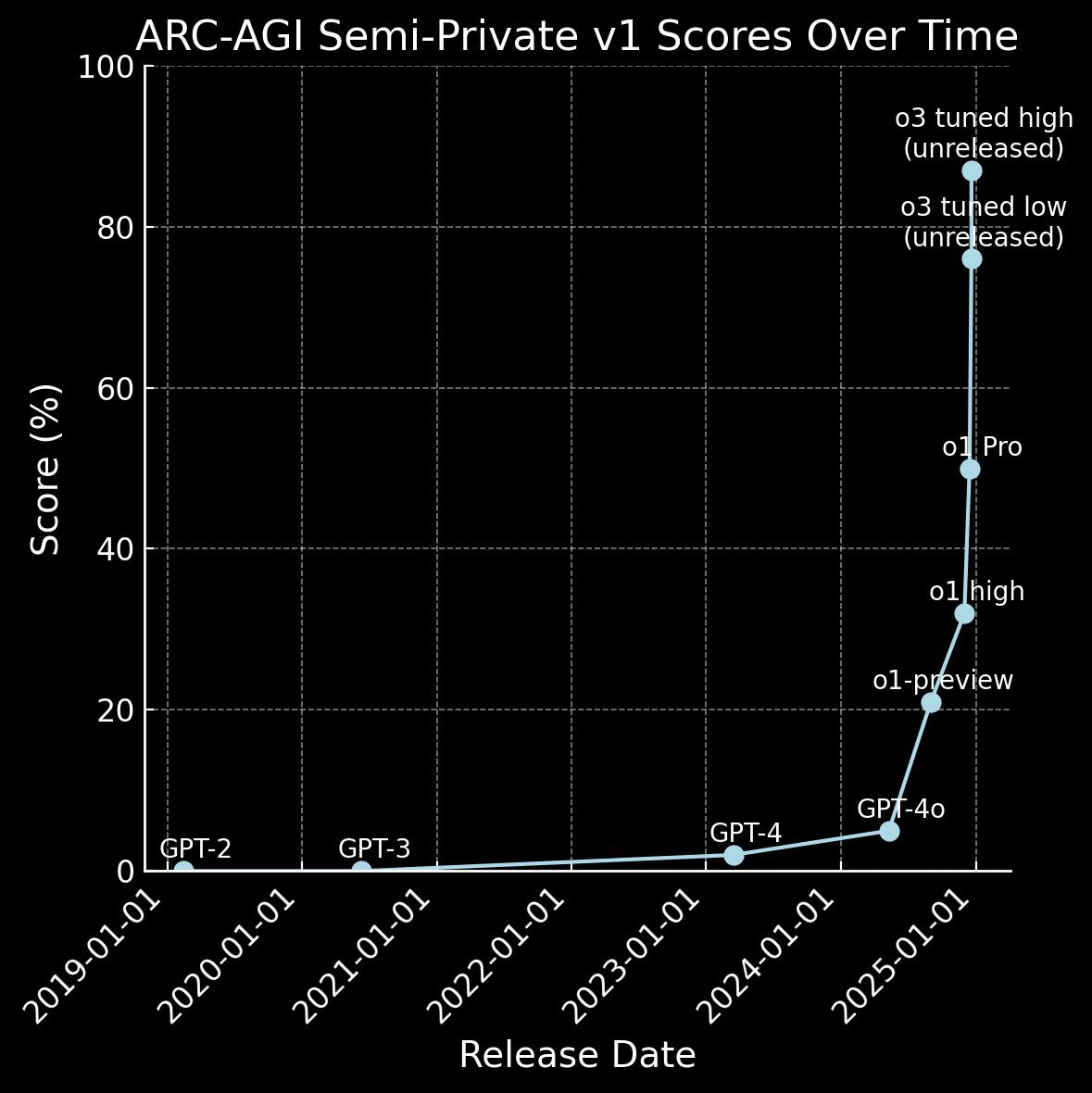
What we see: there is no wall. On the contrary: the only wall that exists is the one that is climbing o3. The development is exponential, it is steep.
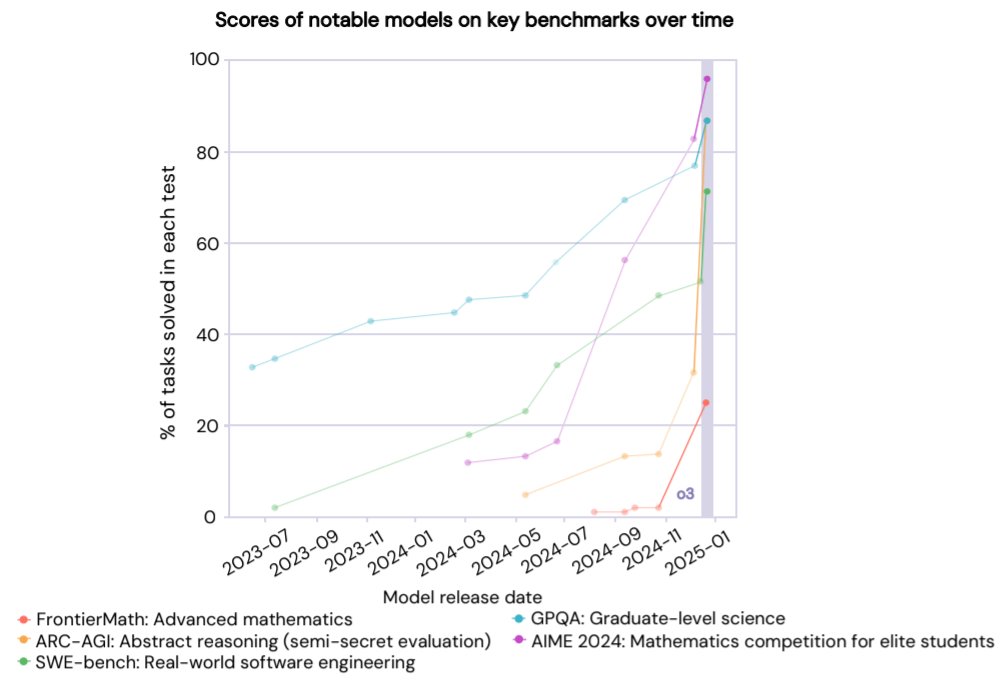
And what is even more important: Noam Brown, OpenAI researcher and head behind the reasoning models, assumes that this rapid pace of development will continue. This means that in another three months we will see a model from OpenAI with o4 that will probably shock us again. And the fact that o4 is already being trained is not a rumor, but was openly communicated by Kevin Weil (CPO) at the World Science Forum in Davos.
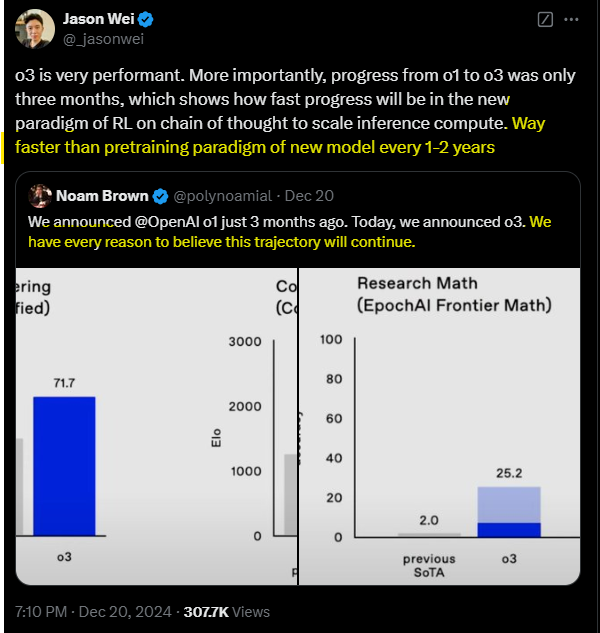
o3 is so important because the scaling and development of reasoning models has now crossed a threshold where it is not only improving quantitatively, but making significant qualitative achievements. Nobody expected it to complete the ARC AGI challenge. And even the developer of the new MathFrontier benchmark did not expect o3 to beat this even more difficult Benchmark by 25% at the first attempt (they expected a success rate of 25% at the end of 2025). o3 is therefore significant, it is a turning point insofar as it represents the new era.

(selbst o3-mini bringt es in FrontierMath inzwischen auf fast 10% genauigkeit)
So let's summarize: o3(mini) represents a turning point. O3-mini gives a taste of what we can expect from future reasoning models and at the same time enables broad usage. For regular users, the rate limit of o3-mini-low has been increased to 150 usage per day and for o3-mini-high to 50, the same limit as for full o1.
The release should certainly also be seen against the background of the extremely successful DeepSeek r1 and enables OpenAI to launch its models even more widely. Full o3 will, as Sam Altman recently said on Reddit, be released in several weeks or a few months; I estimate 4-6 weeks until release of full o3. o4, on the other hand, is already in training and, in the context of OpenAI researcher Noam Brown, can be seen as a similarly strong development leap as from o1 to o3. Before that, however, pro-tier users will get access to o3-Pro, as Sam Altman also made clear. According to Altman, it will be worth the wait.

The AI revolution is unfolding at an unprecedented pace. With o3-mini, we are seeing small models achieve performance levels once thought impossible. As inference efficiency improves and costs decrease, AI intelligence is becoming more accessible to the masses. The era of small, powerful models has begun—and it won’t be long before intelligence is, as some say, ‘too cheap to meter.
—
Get more content from Kim Isenberg—subscribe to FF Daily for free!
 | Kim IsenbergKim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society. |
Reply