- Forward Future Daily
- Posts
- 👾 Peak Data - Part 2
👾 Peak Data - Part 2
AI is evolving beyond “more data, better models.” With real data hitting limits, synthetic data is fueling AI while inference scaling boosts efficiency. Models like DeepSeek show how smarter processing, not just bigger datasets, is driving the next leap toward general intelligence.
Kim Isenberg
February 10, 2025
The Creation of Synthetic Data and Global Players
The generation of synthetic data is a complex process involving several steps:
Data analysis: First, existing real data sets are analyzed to understand their statistical properties, patterns and relationships. This analysis forms the basis for the subsequent modeling of the synthetic data.
Modeling: Based on the insights gained, models are developed that are able to replicate the identified patterns and structures. Generative Adversarial Networks (GANs), which consist of two neural networks – a generator that attempts to create realistic data and a discriminator that attempts to distinguish between real and artificial data – are often used here. Through this interaction, the models learn to generate more and more realistic data.
Generation: The trained model is used to generate new data that statistically resembles real data but does not contain any real information. This makes it possible to produce large amounts of data that can be used to train AI models.
Validation: the generated synthetic data is checked to ensure that it has the desired properties and does not contain any unwanted biases or errors. This step is crucial to ensure the quality and usefulness of the synthetic data.
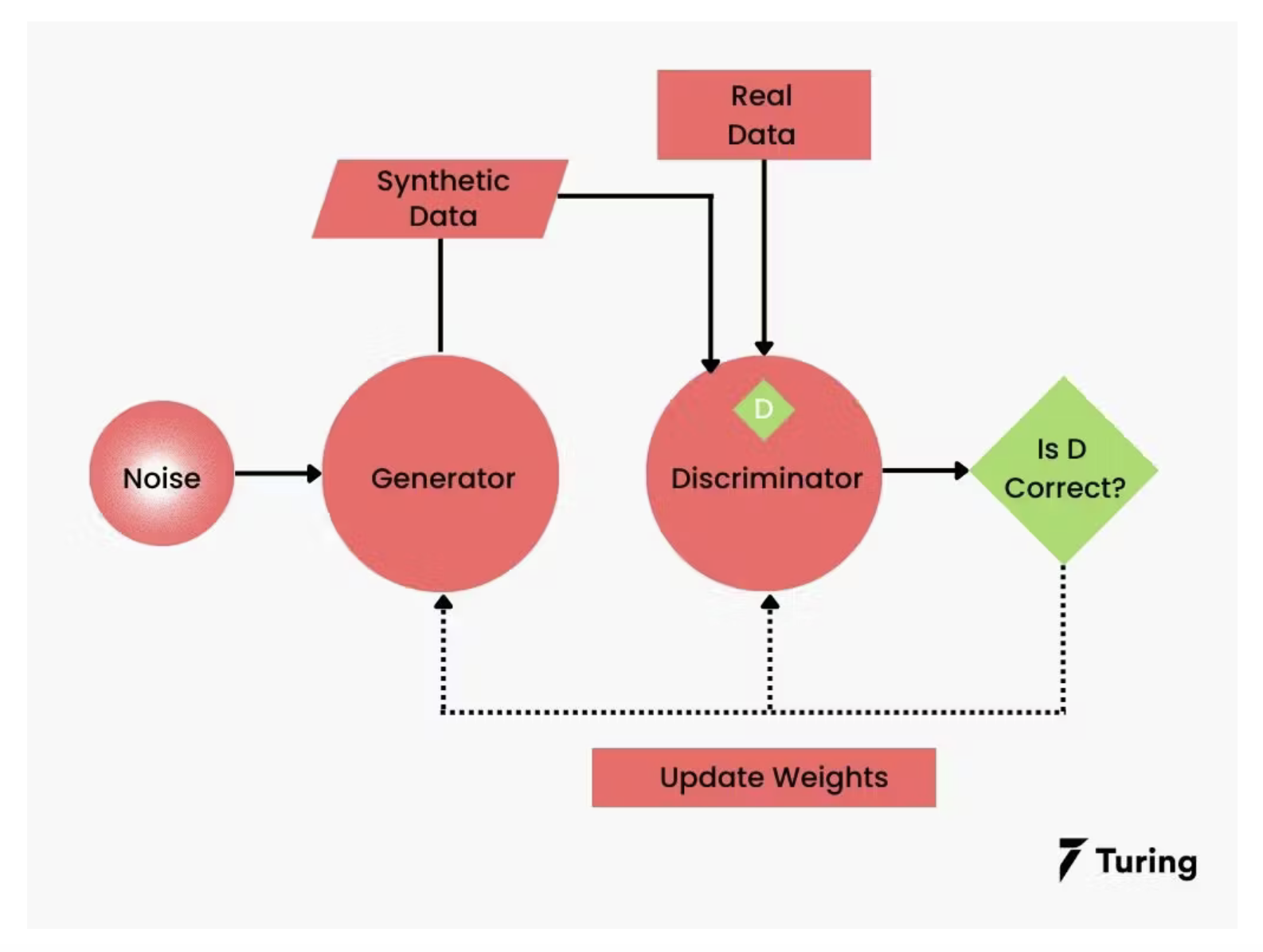
turing.com
In the field of artificial intelligence, several companies have specialized in the generation of synthetic data and have taken on a significant role. These companies differ in their approaches, technologies and application areas, which leads to a diverse landscape of leading players in this sector. After understanding why synthetic data is necessary to counteract the lack of data in pre-training and taking a brief look at how synthetic data is generated, we will now take a look at some of the major players in the field of data generation.
Scale AI is a prominent company focused on providing data solutions for machine learning. With their Scale Synthetic platform, Scale AI offers the ability to supplement real-world data sets with diverse and realistic synthetic data. This helps machine learning teams achieve the desired data distributions and improve the performance of their models. A practical example of how Scale AI's synthetic data is used is the collaboration with Kaleido AI, which has significantly increased the performance of its models by integrating this data.
CEO Alexandr Weng has also made a name for himself as a well-informed insider, talking about the computing power of DeepSeek in an interview at the World Economic Forum in Davos, whose latest model DeepSeek r1 was trained mainly with synthetic data from its reinforcement learning model DeepSeek r1 Zero (more on this below). His statement that DeepSeek actually has access to tens of thousands of GPUs, which are normally out of reach due to embargoes, caused quite a stir.
Another important company is MOSTLY AI from Austria. They specialize in generating synthetic data that mimics real data sets in terms of structure and statistical properties, but does not contain any personal information. This enables companies to conduct privacy-compliant analysis while maintaining the quality and validity of the data. This is a significant aspect, especially in Europe. With its legislation and the EU AI Act, the EU has set essential requirements that have forced AI companies to follow a strict, data protection-compliant set of rules, which discourages some companies (e.g. Meta and xAI) from training their models with European data. In this respect, MOSTLYA AI is particularly important for Europe.

Europe is a challenge for the big AI companies; data protection makes work difficult
TonicAI, based in the USA, also offers solutions for generating synthetic data. Their focus is on providing test data for software development processes to ensure that applications can be tested under realistic conditions without using sensitive or personal data.
Synthesis AI is another US-based company specializing in the creation of synthetic data. They use advanced AI techniques to generate realistic images and videos that can be used to train computer vision models. This is particularly useful in areas such as autonomous driving or facial recognition, where large amounts of visual data are required.
GenRocket, Inc. from the USA offers a platform for generating synthetic test data for various use cases. Their approach enables companies to create customized data sets that meet specific testing requirements while ensuring data integrity and security.
Gretel Labs, Inc., based in the USA, focuses on providing synthetic data generation tools that help developers create privacy-friendly applications. Their platform makes it possible to anonymize sensitive data while maintaining the usefulness of the data for analysis and development purposes.
K2View Ltd. from Israel also offers solutions for generating synthetic data. Their focus is on providing data management and data protection solutions for companies that process large amounts of data and have to meet compliance requirements.
These companies have established themselves with their specialized approaches and technologies in the field of synthetic data and are instrumental in overcoming the challenges of data acquisition, data protection and data quality in the development of AI. This brief overview is intended to give an impression of how diverse the companies in this field are, what their areas of focus are and for which areas synthetic data is generated.
In the following, we will discuss what is probably the most prominent example of synthetic data generation to date: DeepSeek r1 and DeepSeek r1 Zero.
Synthetic Data, Reinforcement Learning, and DeepSeek
In recent weeks, the company DeepSeek has caused quite a stir in the AI community with its model DeepSeek-R1. The innovative training approach is remarkable, as it makes it possible to develop a powerful reasoning model with comparatively little computing effort. A central component of this success is the use of reinforcement learning (RL) to generate synthetic data.
Reinforcement Learning (RL): A model learns by receiving rewards or penalties based on its actions, improving through trial and error. In the context of LLMs, this can involve traditional RL methods like policy optimization (e.g., Proximal Policy Optimization, PPO), value-based approaches (e.g., Q-learning), or hybrid strategies (e.g., actor-critic methods). Example: When training on a prompt like "2 + 2 =", the model receives a reward of +1 for outputting "4" and a penalty of -1 for any other answer. In modern LLMs, rewards are often determined by human-labeled feedback (RLHF) or as we’ll soon learn, with automated scoring methods like GRPO.
The DeepSeek-R1-Zero model was developed to investigate whether it is possible to train a powerful reasoning model using only reinforcement learning, without resorting to manually labeled data. A form of “pure” reinforcement learning was used in which the model learns to develop optimal strategies through trial and error. Although this approach is initially time-consuming, the costly and time-intensive process of data labeling is no longer necessary, which in the long term leads to more efficient and scalable development of reasoning models.
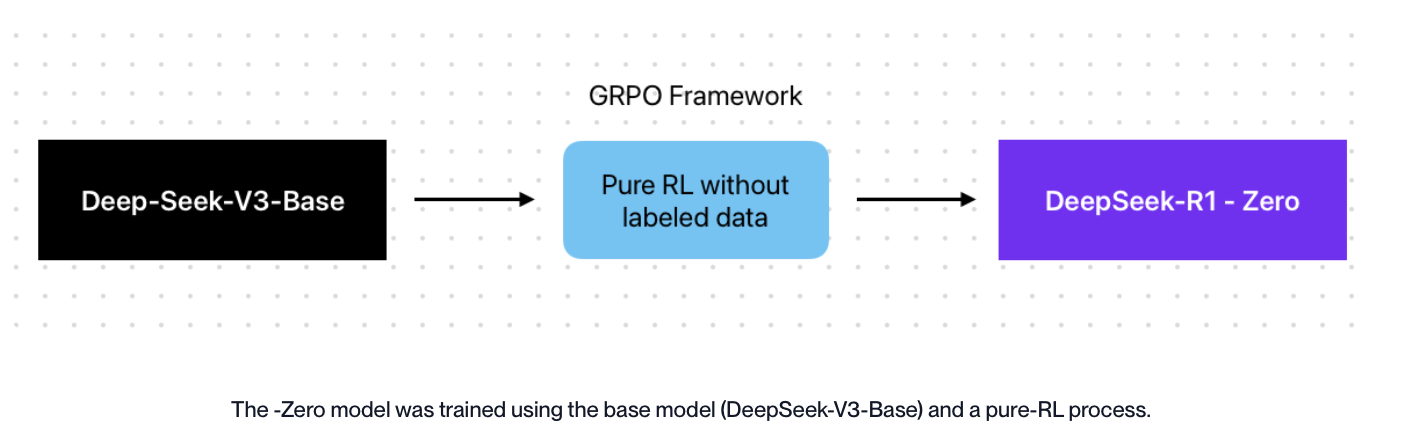
picture: vellum.ai
During the training process of DeepSeek-R1-Zero, various challenges were identified, including limited readability of the generated content and the mixing of different languages within the answers. To address these issues and to further increase performance, DeepSeek developed the DeepSeek-R1 model. This model went through a multi-stage training process:
Initial fine-tuning: The basic model DeepSeek-V3-Base was fine-tuned using a limited amount of “cold start” data to create a solid foundation and improve the readability of the output.
Reinforcement learning: The model was then further trained using reinforcement learning to strengthen its reasoning abilities.
Generation of synthetic data: During RL training, the model generated its own synthetic data by selecting the best examples from successful RL runs.
Fine-tuning with synthetic data: This synthetic data was combined with supervised data from different domains to further refine the model and strengthen its capabilities in different areas.
Final reinforcement learning: In a final phase, the model was retrained using reinforcement learning on a wide range of prompts and scenarios to maximize its generalization ability.
Through this iterative process, DeepSeek-R1 was able to overcome the previously identified challenges and present a model capable of efficiently performing complex reasoning tasks. The combination of reinforcement learning and the generation and use of synthetic data made it possible to develop a powerful model with reduced reliance on real, labeled data.
These developments underscore the potential of reinforcement learning and synthetic data in AI research and could lead the way for future approaches to model development.
What we see in DeepSeek, and what underscores its significance, is how synthetic data can be generated using RL and used to significantly improve AI models. DeepSeek is an impressive achievement that also shows how outstanding results can be realized with a low capital investment.
Conclusion
Data has always played a central role in the development of artificial intelligence. It forms the basis for training models, enables the recognition of patterns and promotes generalization capability. Traditionally, the more data and the larger the models, the more powerful the AI. However, this paradigm of pre-training, in which models are pre-trained with extensive data sets, is increasingly reaching its limits. The availability of high-quality real-world data is limited, and the continuous growth of model sizes is leading to exponentially increasing demands on computing resources and energy consumption.
This is where synthetic data comes into its own. It offers the possibility of creating artificially generated data sets that resemble real data but are free from constraints such as data protection concerns or the lack of availability of specific data types. By using techniques such as reinforcement learning, models like DeepSeek-R1-Zero can generate synthetic data that is used to train other models. This opens up new ways to reduce dependence on real data while still developing powerful AI systems.
At the same time, a new scaling paradigm is emerging: inference scaling. Rather than focusing exclusively on pre-training, more emphasis is being placed on optimizing the inference phase – the phase in which the trained model reacts to new inputs. By using more computing power during inference, models can improve their performance without requiring a proportional increase in training data or model size. For example, OpenAI has shown with its model o1 and o3 that by applying multi-level reasoning during inference, performance in complex tasks can be increased.
This inference scaling makes it possible to overcome the challenges of traditional pre-training. It reduces the dependency on ever larger data sets and models, while at the same time opening up new possibilities for more efficient and powerful AI systems. By combining synthetic data and optimized inference strategies, we can leave the limitations of previous AI training behind and create innovative approaches for future developments.
Just a few days ago, Google presented its latest flagship, Gemini 2.0 Pro, and at the same time proved what has been said here with the published benchmarks. More and better data does lead to better models, but only to a limited extent. Compared to inference scaling, data-driven pre-training seems to be reaching its limits. The effort, the horrendous resources needed for ever larger models are now in a poor ratio to the yield. If you compare Gemini 2.0 Pro with the last reasoning models from OpenAI or DeepSeek, it turns out that the long wait for Gemini 2.0 was only partially worthwhile. Gemini impresses with a long context window and, with the Flash model, good cost efficiency. In benchmarking, however, there is a bland aftertaste when it comes to pure performance.
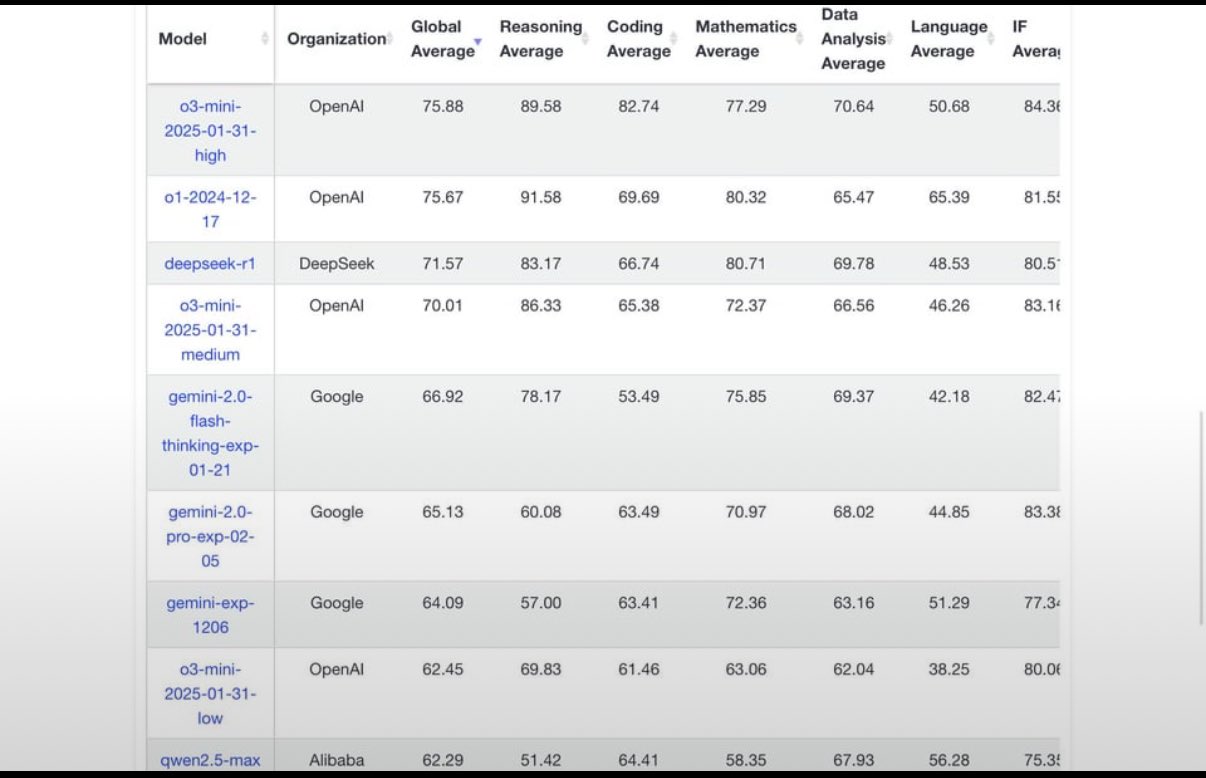
As important as data continues to be, and as essential as synthetic data in particular will continue to be, it is now very clear that a pure focus on pre-training data only improves models to a limited extent. Data will continue to play a central role. However, it can now also be said that the shift in focus from pre-training to inference scaling now enables a significantly better yield. And even though it is not clear how high the total costs of the DeepSeek r1 model were overall, it can be said with relative certainty that training the model was comparatively inexpensive. Back then, data was comparable to gold, but it has lost some of its luster. Again: data is still of paramount importance. But the hype surrounding inference scaling is not without reason. And this new scaling-padigm has at least partially shifted the focus of data. But one thing is still clear. Regardless of what is currently being focused on, AI models as a whole have not reached any limits and will continue to improve significantly and significantly in the future. And general intelligence is thus coming within reach more and more every day.
—
Want more insights from Kim Isenberg? Get AI news, expert takes, and breakthroughs—straight to your inbox. Subscribe to FF Daily (yes, it’s free).
 | Kim IsenbergKim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society. |
|

Reply