
Note: If you haven’t seen Part 2-1, you can read it here.
Training Data
ScaleAI CEO Alexandr Wang gave an interesting insight into the importance of training data in the podcast by venture capital firm Andressen Horowitz (a16z) titled “Human Data is Key to AI: Alex Wang from Scale AI”. He explained that since the introduction and success of GPT-3.5, it has become clear that three areas in particular need to be further developed: Compute (computational capacity), Scale (the number of parameters in a model) and Data (data quality and quantity; Wang thus distinguishes Scale from Compute and Data). Wang emphasizes that the main problem at the moment is the lack of high-quality data. His company, ScaleAI, has therefore specialized in converting unstructured data into high-quality data sets that can be used to train AI models, including through fine-tuning, reinforcement learning from human feedback (RLHF), data labeling and curation.
Wang also explains why, despite the great progress in scaling computing capacity, we do not yet have functional agents for generalized tasks. He attributes this primarily to the lack of suitable training data. While humans are naturally used to combining different tasks and processing information between different applications, AI models lack this ability as there is simply no suitable data to train such complex tasks. For example, it is natural for a human to process data in Excel, transfer it to another tool and then evaluate it further. However, this multitasking ability cannot yet be taught to AI agents, as there is no suitable training data that maps such processes.
Having emphasized with Wang the crucial role of high-quality training data, it becomes clear that the progress of AI models is not driven by the sheer volume of data alone. Rather, algorithmic innovations also play an essential role. One of these innovations that represents a significant step forward is the so-called “Chain of Thought” (CoT) method. This enables models to simulate more complex thought processes by forming chains of reasoning that go beyond simple pattern recognition. CoT has shown that Transformer models are able to form chains of reasoning and thus simulate a rudimentary form of “System 2 thinking” according to Daniel Kahneman. However, it must be emphasized that this “reasoning” in AI models has not yet been fully researched and OpenAI has so far only provided limited insights into the internal processes of its models.
In addition to compute, the ever-improving reasoning naturally also requires electricity as the most important requirement. However, both are necessary (and, as I will explain later, increasingly difficult to obtain) and are mutually dependent. It is commonly calculated that only about 20% of compute is used for training the models and the rest for inference, the process of applying a trained model to new, unknown data to make predictions or decisions based on the learned patterns.
“Of total AI usage, 20% is currently used for the training of models, with the rest going to inference—the individual instances with which the model is tasked. The ratio is expected to evolve to 15:85 by 2028.”
Inference also determines how quickly a model responds to a query. And time plays an increasingly important role in “thinking” models.
“While training is computationally intensive, inference—the phase where the model is used to make predictions—also requires considerable resources, especially for large models. The latency and compute requirements for real-time inference in applications like autonomous driving or real-time language translation necessitate powerful hardware and efficient algorithms.”
Models like OpenAI's o1, which now rely primarily on test-time compute, require significantly more compute by performing multiple “thought steps” using the Chain of Thought process. They therefore require more time for complex questions. It is to be expected that as the models improve, the complexity of the questions we ask the models will also become more complicated. So if we don't want to wait weeks or months for an answer, we need more computing power. But also because more and more people worldwide have access to AI/LM. And more time also requires more electricity.
“We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.”

Although we can clearly see so far that scale significantly improves language models and we now see the challenges with the additional demand for compute and power, for the sake of completeness, the theses that speak against a scale theory should also be mentioned before we look at some empirical evidence on scale in the next step. In my view, the most important theses are anti-scale and system architecture.
The first thesis is that scaling laws are not universally applicable. While the performance of models such as large language models shows that they improve with increasing data volume and computing power, these improvements are based on proxy metrics that often do not reflect the actual goal or functionality that one would expect from an AGI. This means that the measured performance of these models in specific contexts does not necessarily reflect the general cognitive performance that would be necessary for AGI.
Another argument is that the development towards AGI requires more than just large models. It is emphasized that the human brain cannot be modeled simply by adding more neurons or more training data. Instead, it requires a complex system architecture that integrates various functional subsystems that work together in a balanced way. This complexity is currently lacking in most AI systems that rely on scaling-based approaches. (however, I indirectly address a possible solution through ScaleAI when addressing the question of agents)
It may sound unsatisfactory, but the ultimate test of whether a statement is true is whether it can be practically demonstrated. In this respect, the most important thing at the moment seems to be to push ahead with scaling in order to prove that the above anti-scaling theses are true or false. After all, we have at least been able to observe in recent months that generalization capability and reasoning have increased significantly as a result of algorithmic improvements (CoT) and more scale.
2.3 Some important Graphs
First of all, even though I am aware of the discussion within the community about Aschenbrenner's blog and the accuracy of his data and projections, I still consider Aschenbrenner's blog to be fundamentally valid and underpinned by a great deal of knowledge from his work as an OpenAI employee. There are some justified criticisms of his blog, but overall I think his analysis is sound.
The graph shows the development of the computational effort (in FLOPs, i.e. “Floating Point Operations per Second”) for training models in different domains of artificial intelligence over time, from the 1980s to 2025. Over the years, the computational effort required to train AI models has increased dramatically. This is reflected in the steady increase in resources required for advanced AI systems. In recent years, it has also become particularly clear that many models across different domains require significantly more computing power than previous approaches.
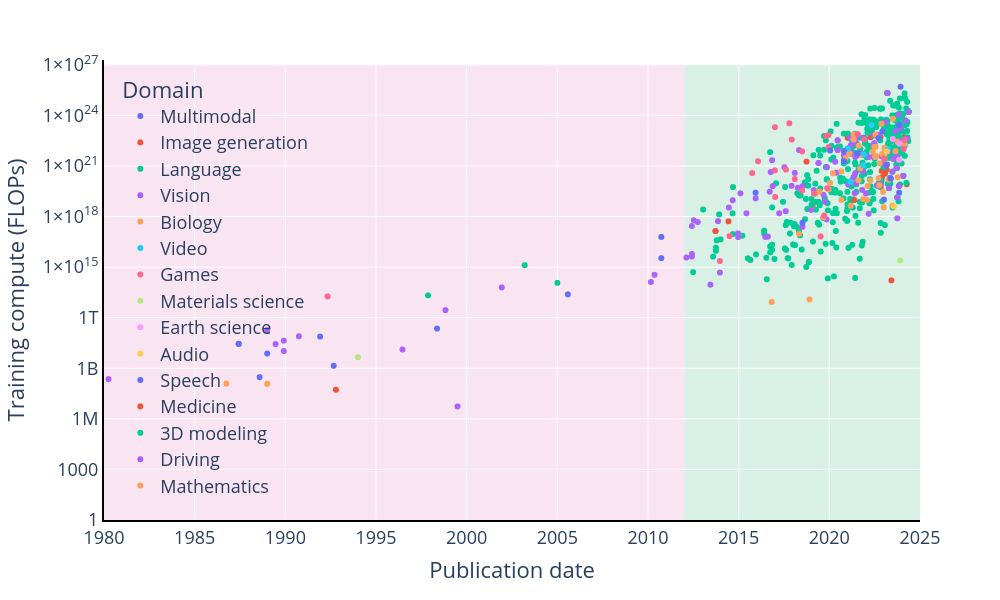
“Training these massive models requires an enormous amount of computational power. The data shows a clear trend: as the number of parameters increases, so does the training compute, measured in floating-point operations per second (FLOP). This relationship is evident in the scatter plot below, which depicts the exponential rise of training computation required for various AI models across various domains. The exponential growth in training compute has significant energy implications. Training large models consumes substantial electricity, contributing to the overall carbon footprint of AI development.”
It is to be expected that the demand for resources will continue to increase significantly.

The epochai.org graph shows even more clearly that the computing power required to train AI models is roughly doubling every six months.
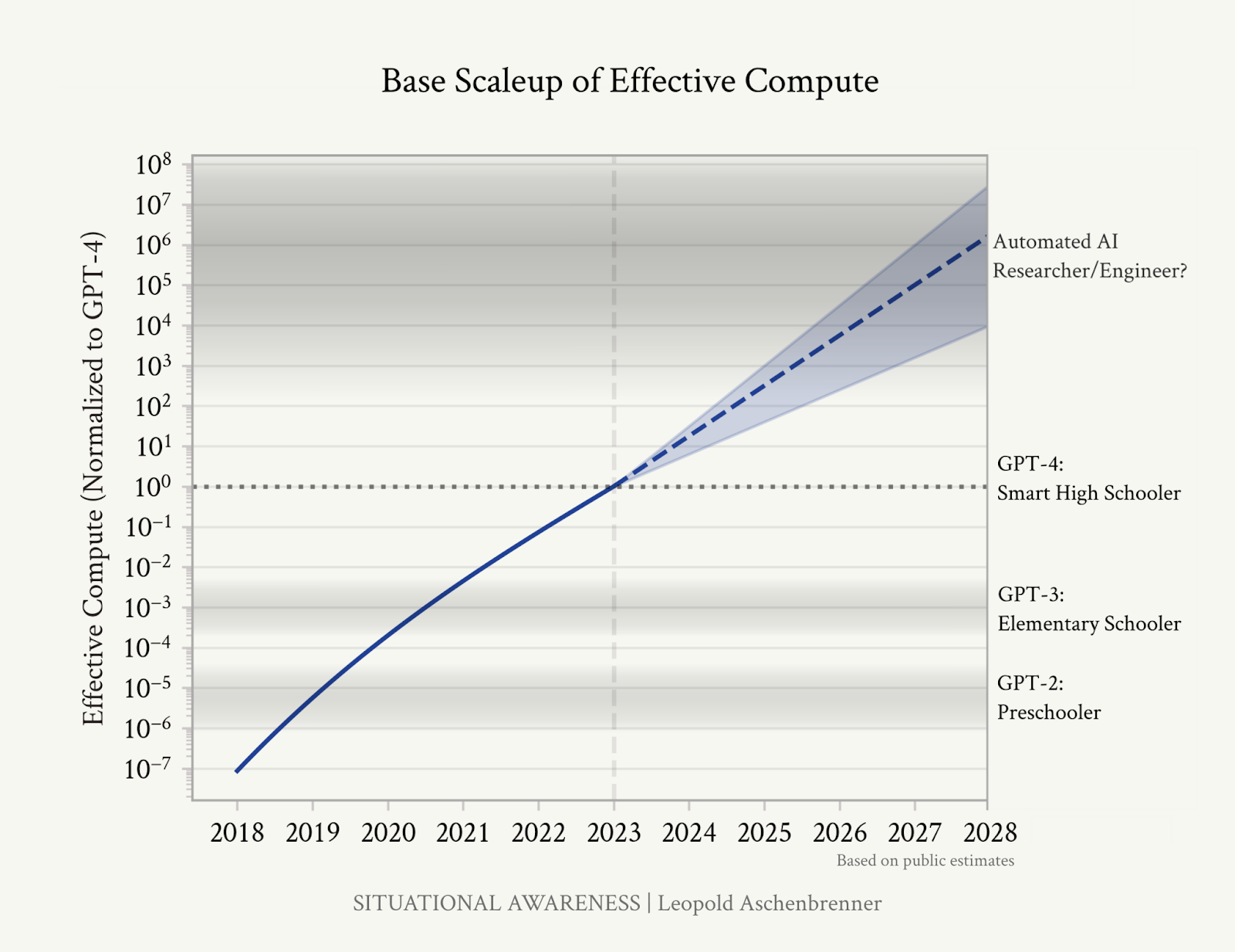
The graph shows that the computing power of AI models has increased exponentially in recent years and is expected to continue to grow rapidly. With increasing computing power, AI models could potentially develop capabilities that resemble autonomous researchers/engineers.
At the same time, however, Aschenbrenner points out in his blog that we should not underestimate the improvement of models through algorithmic improvement and that significant efficiency gains can be expected here as well.

It is obvious that the development of data processing is accompanied by numerous problems. Currently, data centers worldwide consume about 2% of all energy. “Porter says that while 10-20% of data center energy in the U.S. is currently consumed by AI, this percentage will probably ‘increase significantly’ in the future.”

In particular, a comparison of a request to a GenAI with a normal Google request highlights.
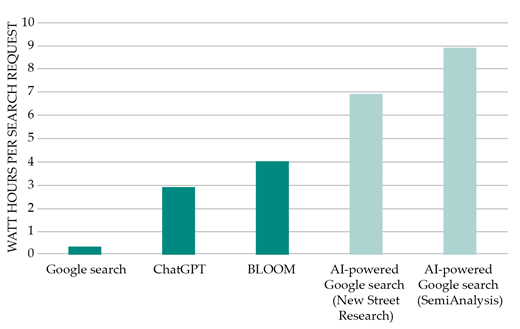
As outlined above, the demand for computing power is increasing in line with the growth in electricity. “Researchers recently found that the cost of the computational power required to train these models is doubling all nine months, with no slowdown in sight.”
The empirical study shows that the computational effort for training and inference is constantly increasing. The increase in compute will lead to more intelligent models, as we have recently seen with OpenAI's model o1. However, the additional demand for computing power comes at the expense of electricity consumption. This demand is also growing exponentially, presenting us with completely new challenges.
3. Some final remarks
“From a software algorithmic perspective: it seems The more Data you throw at a problem the more parameters the more flops you throw at the model the better compression code you learn the better performance. No upper bounce there will be for AI.”
Guillaume Verdon, Founder & CEO of ExtropicAI (known on X as @basedjeffbezoz) is a physicist and leading researcher at Extropic.ai. He is working on a new generation of AI accelerator chips based on an innovative approach of superconducting processors that work at low temperatures. A genius in his scientific field. The quote above is from a recent keynote and he, too, says that AI scaling currently has no end in sight – but that energy is the biggest bottleneck.
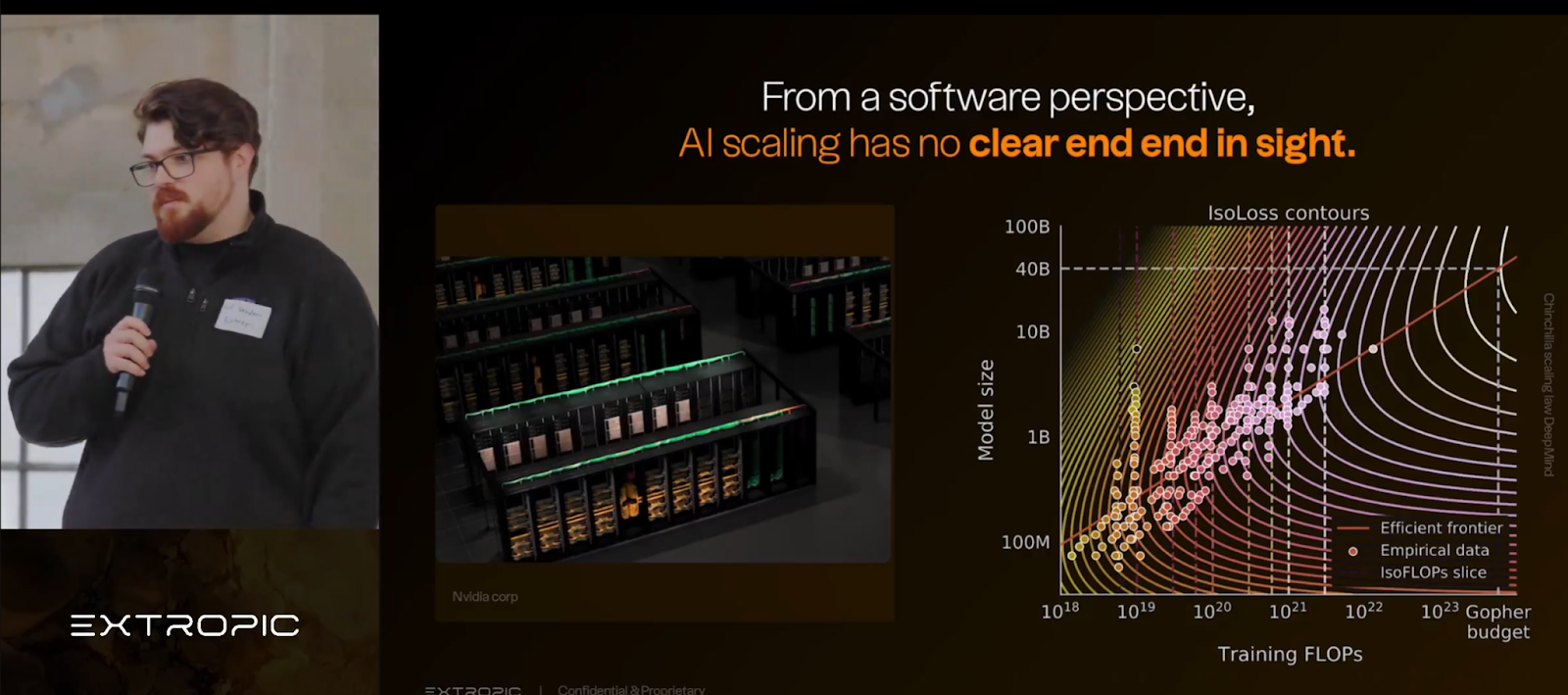

Therefore, the conclusion of “the science” is also quite understandable in the light of the issues discussed here.
“The exponential growth in AI model parameters and the corresponding increase in computational requirements for training and inference have profound implications for energy usage and hardware costs. As AI continues to evolve, addressing these challenges is essential to ensure sustainable and equitable development.”
And although GPUs are becoming more efficient, the power requirement is increasing more than the energy efficiency of more efficient chips can compensate for!
“It’s important to note that each subsequent generation is likely to be more power-efficient than the last generation, such as the H100 reportedly boasting 3x better performance-per-watt than the A100, meaning it can deliver more TFLOPS per watt and complete more work for the same power consumption. However, GPUs are becoming more powerful in order to support trillion-plus large language models. The result is that AI requires more power consumption with each future generation of AI acceleration.”
and
“But de Vries and others argue that AI will grow so rapidly that it will overwhelm any further increases in efficiency that can be wrung out of computing hardware, which they say is already reaching the limits of Moore’s law for chip feature sizes”
Let's summarize: models become more intelligent through scaling. There is general consensus on this. The biggest hurdles on the road to AGI seem to have been overcome and o1 currently unanimously shows how powerful LLMs can become on transformative architecture, although there are also scientific theses that consider scaling to be insufficient for AGI.
Computing power will continue to increase and the problem of agent training has also been well illuminated and partially solved by Wang. In addition, algorithmic improvement still offers plenty of room for efficiency gains. In short, it seems that we really only need scale to achieve AGI, although of course there is still a big unknown that could throw a wrench in our plans.
I have already pointed out the challenges associated with this in some places. Computers and electricity. The continued high demand for GPUs could delay the rapid realization of AGI. However, the energy problem arises more during computing than with any iterative, new series of GPUs, their power requirements increase more rapidly than their efficiency improves the models. This could be the bottleneck that needs to be resolved.
This question will be discussed in more detail in the third part.
Subscribe to the Forward Future Newsletter to have it delivered straight to your inbox.
About the author



