
Longer context windows show us the promise of what is possible. They will enable entirely new capabilities and help developers build much more useful models and applications.
The development of large language models has enabled remarkable progress in natural language processing and generation in recent years. These models are able to understand complex texts, generate human-sounding responses, and perform a variety of tasks, from machine translation (Google Translate, DeepL) to text generation. But despite their impressive potential, they face technical limitations that restrict their usefulness and performance. One of these limitations is the so-called context window size.
The context window defines how many characters, words or tokens a model can process and “keep in mind” at the same time to generate contextually meaningful responses. The larger the context window, the more information can be included at once, which is crucial for many applications such as document summarization, legal analysis, or processing conversational histories. Nevertheless, the length of this window is limited – a fact that results from both technical and economic reasons.
The limitation of the context window brings several challenges. First, the model often cannot take into account all the context needed, leading to erroneous or superficial responses. Second, users often have to manually trim or adjust the input to highlight relevant information. This makes it difficult to use LLMs in scenarios where context across longer texts is crucial, such as in science, medicine, or literary analysis.
But why does this limitation even exist? The cause lies in the architecture and computational requirements of modern language models. LLMs such as GPT or BERT are based on so-called transformer networks, whose attention mechanism scales exponentially with the input length. This means that the computational load and memory requirements increase significantly with each additional token, which sets both technical and economic limits. At the same time, a context window that is too large can lead to potential problems such as information overload or a deterioration in model precision.
In the face of these challenges, the question arises: What approaches are there to overcome this limitation? Researchers and developers are working on innovative solutions such as the efficient use of storage resources, new attention mechanisms and hybrid architectures that can process longer contexts. The goal is to develop models that are scalable on the one hand and on the other hand can better integrate relevant information across large sections of text.
This paper addresses the following aspects: What is the context window? Why does it represent a limitation? And what approaches could help to solve this problem in the future? First, the functioning and relevance of the context window is explained before the underlying challenges and possible solutions are discussed.

The origin of the Transformer architecture: the famous paper “Attention is all you need”
What is a context-window and why is it relevant?
“A context window refers to the maximum amount of text an LLM (Large Language Model) can consider at one time when generating responses or processing input. This determines how much prior information the model can use to make decisions or generate coherent and relevant responses.
The size of a context window varies from model to model, and is rapidly growing in size as LLM development progresses. The context window of GPT-3, at the time it was first released, was 2,049 tokens (around 1,000 words). At the time of this writing, LLM context windows typically range from a few thousand to hundreds of thousands of tokens, or even millions for some models.”
The context window is a central part of how large language models work. It refers to the maximum number of units a model can process and “remember” at the same time to generate contextual responses. These units are measured in tokens, not words or letters. Tokens are the smallest textual building blocks a model understands and processes. A token can be a complete word, a word fragment, or even a single character, depending on the tokenization method used. For example, the sentence “This is an example” could be broken down into five tokens: This, is, an, example, and...
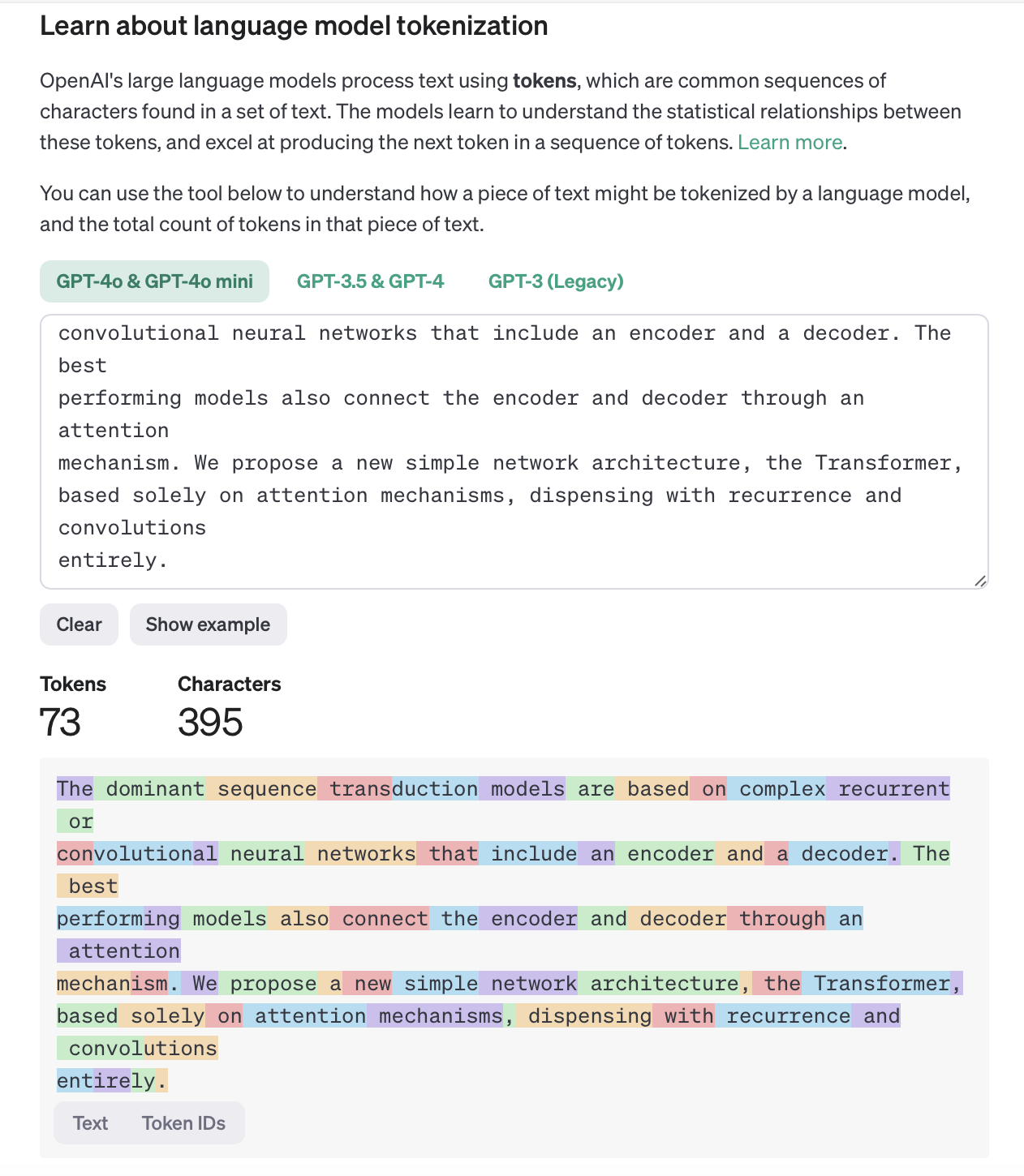
An example of how sentences and words are tokenized https://platform.openai.com/tokenizer
Tokens are used instead of words because natural language is highly variable. Words can vary greatly in length, frequency and structure. A tokenization system makes it possible to break the text down into standardized units that the model can process efficiently. Furthermore, many languages have prefixes, suffixes and compound words that can be more easily broken down and analyzed using a token-based method. This increases the flexibility and precision of the model when processing different languages and text structures.
“At its core, a token is the smallest unit into which text data can be broken down for an AI model to process. Think of it as similar to how we might break sentences into words or characters. However, for AI, especially in the context of language models, these tokens can represent a character, a word, or even larger chunks of text like phrases, depending on the model and its configuration.”
Another reason is the technical basis of modern language models. These models work with vectors, mathematical representations that encode the meaning of a token in the context of the entire text. Tokenization reduces the text to a form that can be easily converted into such vectors. Processing words of different lengths in their entirety would significantly impair the efficiency and consistency of this mathematical representation.
medium.com Aman Singh
“Data Representation: Tokens serve as the bridge between raw human language and a format that AI models can process. Every token is converted into a numerical format (often a high-dimensional vector) using embeddings. These numerical representations capture the semantic essence of the token and can be processed by neural networks.”
The context window is the upper limit on the number of tokens that the model can take into account simultaneously during a calculation. Within this window, the model analyzes the relationship between the tokens in order to understand the context and generate predictions or responses based on it. For example, a model with a smaller context window is not able to retain information from a longer text or conversation, which can cause it to lose the reference to earlier statements or sentences.
“The context window also determines the breadth and types of information the model can consider for each decision point, impacting the accuracy and relevance of the model’s outputs. For example, models with larger context windows can accept not only textual prompts but also entire documents, images, videos, or even a combination of multiple files and formats. This opens up new use cases and allows users to interact with LLMs in new ways.”
The length of the context window is determined by the architecture of the model. In most cases, this is based on the so-called transformer models, which use the mechanism of self-attention (“attention mechanism”). This mechanism allows the model to analyze the context between all tokens in the context window. However, the calculations for this attention increase quadratically with the number of tokens, which puts a significant strain on computing resources. It is not an exponential increase, but a quadratic one.
Here is a brief overview of the development:
Year | Model | Context-window / tokens |
2022 | GPT-3 | 2049 |
2023 | GPT-4 | 8,192 and 32,768 |
2023 | GPT-4 Turbo | 128k |
2023 | Claude 2 | 200k |
2024 | Claude 3.5 Sonnet | 200k |
2024 | Gemini 1.5 Pro | 1m - 10m |
(2,049 tokens (around 1,000 words) (Numbers and data from kolena.com))
—
Subscribe to FF Daily to get the next article in this series, The Context Window Dilemma | Part II.

Kim Isenberg
Kim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society.

