Thinking, Fast and Slow
“Enabling LLMs to improve their outputs by using more test-time computation is a critical step towards building generally self-improving agents that can operate on open-ended natural language.”
In recent years, the rapid development of artificial intelligence has produced increasingly powerful models that are used in a wide range of applications from speech processing and image recognition to autonomous driving. The success of many systems is based on the immense computing power required to train such models. Until now, the focus has been on maximizing efficiency and accuracy during the training phase. However, pre-training in particular, i.e. scaling with more and more data, is beginning to come to an end, as even greats like Ilya Sutskever say (“But pre-training as we know it will unquestionably end”). The reason for this is that the internet only offers a finite amount of high-quality data for training AI models. Sutskever compares data to fossil fuels that will eventually run out. He talks about “peak data”, the point at which the amount of available data stops growing. We are also faced with the problem that although computing power continues to increase, adding more data no longer leads to proportional increases in the performance of AI models. This means that simply increasing the amount of data no longer brings significant improvements.
However, a new methodology is increasingly coming to the fore: test-time compute (TTC). Test-time compute refers to the process of using additional computing resources during the inference phase - the phase in which a trained model is applied to new data - in order to achieve better results. Traditionally, the training and inference phases have been strictly separated: while training is typically performed on high-performance computers with expensive GPUs or TPUs, inference is often performed on devices with limited computing power such as smartphones or embedded systems. Test-Time-Compute breaks this assumption by blurring the line between training and inference and using adaptive mechanisms to dynamically improve model performance even after training is complete.
The breakthrough of test-time compute lies above all in its ability to combine flexibility and precision. Through the targeted use of additional computing operations during inference, models can react to changes in the environment or in the input data. One example of this is the use of optimization algorithms that adapt the model directly to the specific input data. This enables a type of “local adaptation” that significantly increases performance. The enormous potential of this technology is particularly evident in applications such as medical image processing or robotics, where even the smallest inaccuracies can have serious consequences.
The innovative power of test-time compute lies not only in the increase in accuracy, but also in the reduction of computational effort during training. Instead of optimizing models rigidly and universally for all possible scenarios, TTC allows for targeted fine-tuning, which makes the training phase more efficient. At the same time, it opens up possibilities for more resource-efficient AI solutions, as the focus is on adaptation during use.
However, this innovative approach raises a number of questions. What makes test-time compute so special compared to traditional optimization methods? How much further can this technique be developed and what technological advances are needed to bring it to its full potential? It is clear that TTC requires enormous computing resources, especially during the inference phase. But how can this additional “compute demand” be managed efficiently? What role do advances in hardware, such as specialized processors or energy-efficient chips, play in this development? And finally, are there limits to test-time compute, whether due to physical barriers, energy consumption or cost?
These questions are not just of an academic nature, but are crucial for the future design of AI systems. Test-time compute promises nothing less than a paradigm shift in the way we train and use models - a development that invites us to rethink our previous notions of efficiency and optimization. But first, let's take a look at what TTC actually is.
What Is Test-Time Compute?
“Humans tend to think for longer on difficult problems to reliably improve their decisions. Can we instill a similar capability into today’s large language models (LLMs)? More specifically, given a challenging input query, can we enable language models to most effectively make use of additional computation at test time so as to improve the accuracy of their response?”
The quote above is, in a sense, the initial question that prompted scientists to look for a solution to make the LLM even better. And it is no coincidence that the title of this analysis is the title of Daniel Kahnemann's opus magnum, because Google's opening quote is based on Daniel Kahnemann's theoretical framework. Kahnemann assumes that we humans think in two systems, system 1 and system 2. This theory earned him the Nobel Prize in 2004 and is still known today in his book Thinking fast and slow.
Kahnemann assumes that system 1 is the so-called intuitive fast thinking, system 2 the slow “thinking”, so that one can divide thinking into processes.
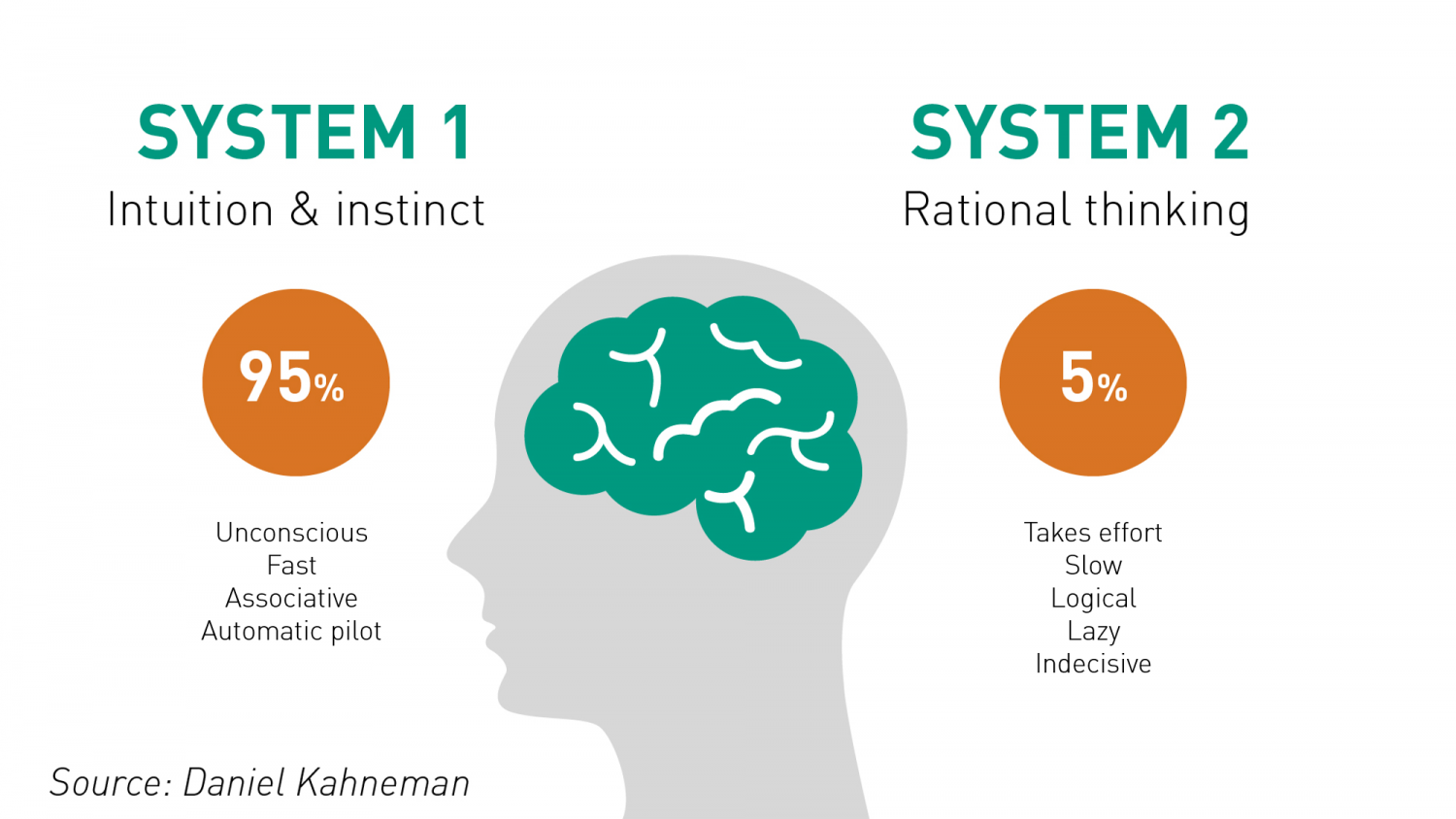
A key question that arises in this context is: How can System 2 thinking, the slow, deliberate and reflective thinking described by Daniel Kahnemann, be integrated into Large Language Models (LLMs)? Currently, LLMs are structured primarily for System 1 thinking – the fast, automatic and intuitive processing of information. This is in the nature of their design, as token generation is based on probabilities. The models select the next token from a list of possible continuations, always following the most likely option. Because of this, they resemble what Timnit Gebru has called a “stochastic parrot”: they replicate patterns without actually “thinking”.
System 1 thinking is inherent in LLMs, which is reflected in the architecture of the transformer (as in Attention Is All You Need). This architecture allows for efficient processing and weighting of information, but primarily supports the “intuitive” generation of text based on statistical probabilities. There are no internal mechanisms that could replicate conscious, reflective or lengthy thought – the core feature of system 2 thinking.
In order to transfer system 2 thinking to LLMs, new approaches are therefore needed that overcome the limitations of previous models. This is where test-time compute (TTC) comes into play, which addresses precisely this shortcoming through adaptive and iterative mechanisms. TTC enables models to use additional computing resources during inference to generate and evaluate multiple possible solutions and finally select the best one. This corresponds to a form of “prolonged thinking” in which the model questions and refines its initial answers.
Such an approach could be supported by implementing verifier mechanisms that assess the quality of intermediate solutions and thus promote the reflection process. In addition, recurrent feedback loops could be introduced that allow the model to review past responses and make adjustments. These mechanisms would represent a shift away from a purely statistical approach towards a multi-stage, conscious decision-making process.
The integration of system-2 thinking into LLMs not only opens up new technical possibilities, but could also significantly expand the range of applications for the models. This would be a paradigmatic advance, particularly in areas that require precise, well-thought-out and context-aware responses – such as legal analysis, medical diagnoses or philosophical argumentation. It would mark the transition from mere language generators to real problem solvers that not only replicate patterns but consciously “think”.
The term “test time” is used historically and conceptually in research and practice, although the term “inference phase” would be technically more precise. The difference in naming depends on the context in which the terms originated and on different emphases in AI research and application. It could therefore also be called inference-compute.
The Beginning With OpenAI’s Q*
A turning point in the development of reasoning models was the emergence of OpenAI's mysterious project “Q*”. First mentioned in November 2023, Q* was designed as an experimental model that attracted attention for its extraordinary performance in mathematical benchmarks. The model's results suggested that OpenAI was breaking new ground, moving away from purely statistical text generators and towards models that sought to develop a genuine understanding of complex tasks.
In July 2024, Reuters reported that OpenAI was working on another model, codenamed “Strawberry”, which later became known as “o1”. This model marked a significant advance in AI research. On September 12, 2024, OpenAI released the “o1-preview” and “o1-mini” models as part of the “Strawberry” series. They were specifically designed to solve complex problems in science, programming, and mathematics through extended processing steps.
What made these models special was the introduction of the so-called Chain of Thought (CoT) method. This technique enables the models to break down complex tasks into smaller, logically consecutive steps. In this way, CoT emulates human, step-by-step thinking, in which a problem is divided into subtasks and worked on systematically. An impressive example of the o1 model's capabilities was its result in the qualification test for the International Mathematical Olympiad: at 83%, it significantly exceeded the 13% achieved by the previous GPT-4o model.
Chain of Thought (CoT) is an approach in which models perform additional steps during the inference to solve problems step by step. This process requires test-time compute (the compute effort during runtime) because the model performs more operations and longer processing steps. As it turned out, this is also very efficient, so that even much larger models can be outperformed using TTC.
“Additionally, in a FLOPs-matched evaluation, we find that on problems where a smaller base model attains somewhat non-trivial success rates, test-time compute can be used to outperform a 14×larger model.”
CoT enables models to solve complex problems by thinking incrementally, which leads to increased accuracy. However, this approach requires more computational resources during the inference phase because the model performs additional calculations for the intermediate stages. This generates the now widely used term “reasoning” in language use. It can be translated as logical, longer thinking.
“Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason.”
But besides test-time compute, there is also the similar-sounding term train-time compute and test-time training. Since the terms are related and have a meaning in the context of reasoning, they have to be differentiated and kept apart. For a basic understanding of test-time compute, I would like to define and explain the three terms in more detail below.
—
Get the next article in this series by subscribing to FF Daily for free.

Kim Isenberg
Kim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society.

