- Forward Future Daily
- Posts
- 👾 The Magic of Prolonged Thinking: Test-Time Compute | Part 2
👾 The Magic of Prolonged Thinking: Test-Time Compute | Part 2
A Comprehensive Exploration of Train-Time Compute, Test-Time Compute, and Test-Time Training for Next-Generation Performance
Kim Isenberg
January 20, 2025
TTC, TTT and TTT in Relation
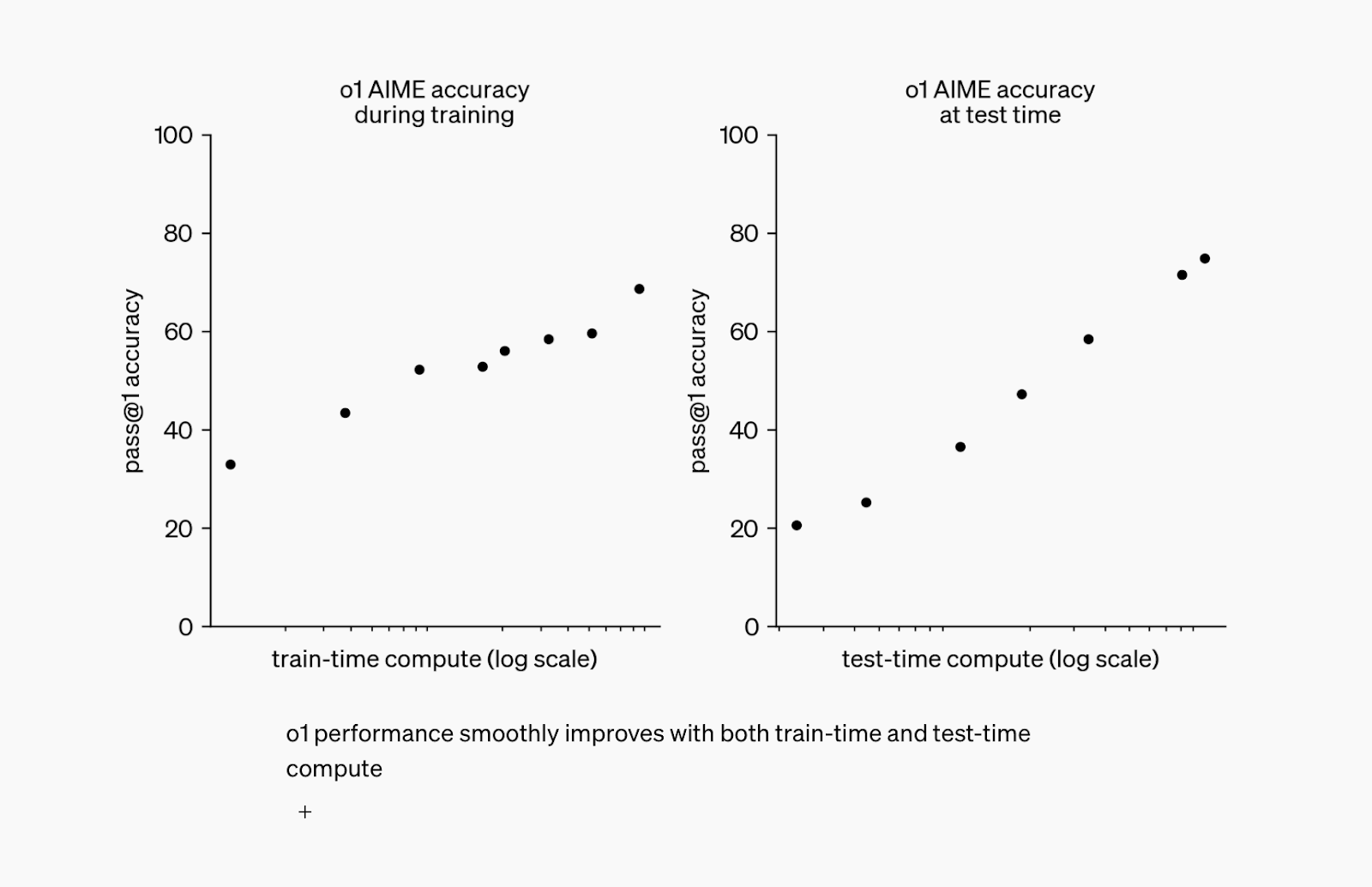
“Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).”
Train-Time Compute (TTC) refers to the total computing power required during the training phase of a model, i.e. the period in which the model recognizes patterns in a large amount of data and learns from them. A particularly important part of this is the pre-training, in which the model is usually trained on a wide range of data sets to develop a general understanding. Methods such as reinforcement learning are often used before or after this pre-training to improve the model in a targeted way. In addition, the concept of “Chain of Thought” (CoT) plays a role, in which the model learns to answer complex questions in several mental steps and thus expand its ability to draw conclusions.
After training comes the deployment phase, in which a distinction is made between test-time compute (TTC) and test-time training (TTT). In test-time compute, the model uses only the skills it has already learned during application. It processes new input and provides output (e.g. answers in the case of language models) without changing its internal parameters – CoT can be used here to achieve more precise results through multi-level thought patterns. In contrast, with test-time training, the model does not remain static: it continues to learn during use by completing additional training steps. A language model, for example, could adapt to a new dialect and thus improve its responses step by step. However, this process is more computationally intensive because the model actively updates its parameters. In other words, while test-time compute is like a musician playing their practiced notes, test-time training is like a musician learning a new instrument in the middle of a concert in order to be able to react even more flexibly.
Both methods make models more powerful in their application, but differ significantly in the way the model interacts with the data and how much computing power is required. In my view, both approaches have their strengths: test-time compute enables fast and efficient applications, while test-time training is particularly exciting when models are to continue learning and optimizing themselves during operation.
“TTT significantly improves performance on ARC tasks, achieving up to 6×improvement in accuracy compared to base fine-tuned models; applying TTT to an 8B-parameter language model, we achieve 53% accuracy on the ARC’s public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches. (...) test-time training (TTT), in which models are updated through explicit gradient steps based on test-time inputs (Krause et al., 2018; 2019). This method differs from standard fine-tuning as it operates in an extremely low-data regime typically via an unsupervised objective on a single input, or a supervised objective applied to one or two in-context labeled examples.”
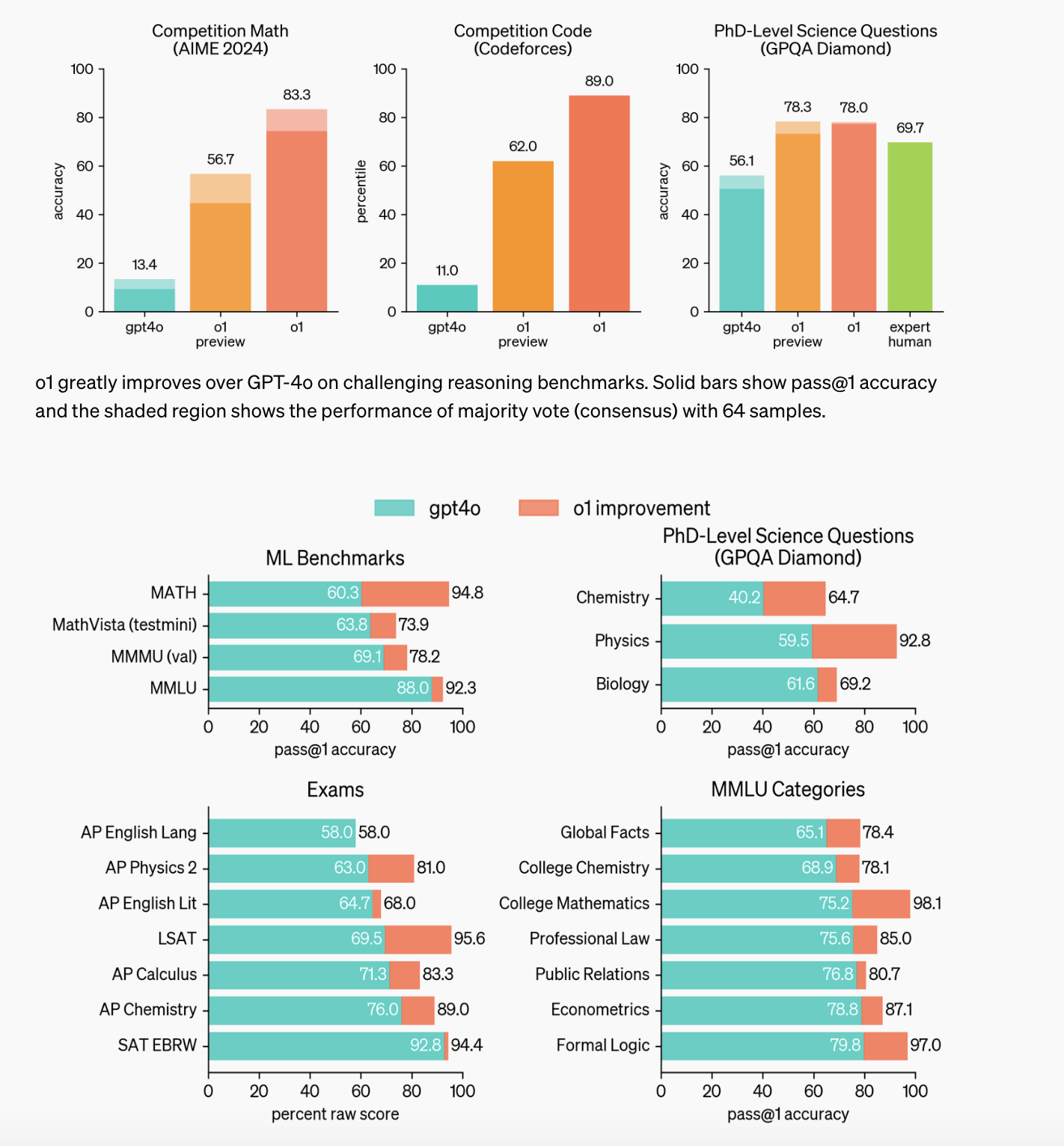
Pioneering Results Using Reasoning and TTC
What makes test-time compute so exciting is that it allows us to retrieve the capabilities of a model during its actual application in a precise and efficient way. For language models like OpenAI's o1 model, this means that they can draw on the knowledge they have already learned with every request and make complex inferences in real time. In contrast to classical approaches, in which models are fixed once they have been trained, TTC focuses on the dynamic retrieval of learned patterns. This allows the o1 model to react immediately to specific questions or situations by focusing its computing power on exactly those parts of the model that are relevant for the respective task. This was a real breakthrough, as it drastically reduced the time and resources required for the application without sacrificing the accuracy or complexity of the possible answers. At the same time, the o1 model set new standards in reasoning: it is able to link several mental steps in a chain of thought (CoT), for example to provide a comprehensible derivation for ambiguous questions. This achieves a new level of efficiency, particularly in areas such as machine language processing, automatic code generation or complex data analysis. Where previously more calculation steps were necessary, the o1 model accesses its internally represented knowledge structures in a more targeted manner during application and can break down complicated content more easily. This has significantly lowered the barrier to the versatile use of artificial intelligence in real-time applications – a milestone that has not only caused a sensation in research circles, but has also advanced numerous practical application scenarios. And there is no end in sight, as OpenAI itself writes on its website (and has recently also made clear with o3):
“o1 significantly advances the state-of-the-art in AI reasoning. We plan to release improved versions of this model as we continue iterating. We expect these new reasoning capabilities will improve our ability to align models to human values and principles. We believe o1 – and its successors – will unlock many new use cases for AI in science, coding, math, and related fields. We are excited for users and API developers to discover how it can improve their daily work.”
The further development of AI models depends crucially on how effectively and flexibly they can react to new challenges. While train-time compute lays the foundation for learning general patterns and skills, test-time compute and test-time training enable specific optimizations during application. Test-time compute is efficient and fast because it uses the skills that have already been learned without any additional adjustments. This is particularly important in scenarios where stable and reproducible results are required. Test-time training, on the other hand, opens the door to dynamic, adaptable models that can continuously evolve during use. This approach, which is realized through targeted gradient steps and minimal additional data input, could become indispensable in areas such as personalized applications or adaptation to specific contexts.
Combining these approaches has the potential to shape the next generation of AI systems. Efficient reasoning, as enabled by chain-of-thought mechanisms, coupled with the ability to continuously learn through test-time training, could lead to models that are not only more powerful but also more adaptable and resource-efficient. This marks a paradigm shift: away from static systems and towards dynamic, learning AI applications that can optimally adapt to the task at hand – a development that will undoubtedly change the way we use AI forever.
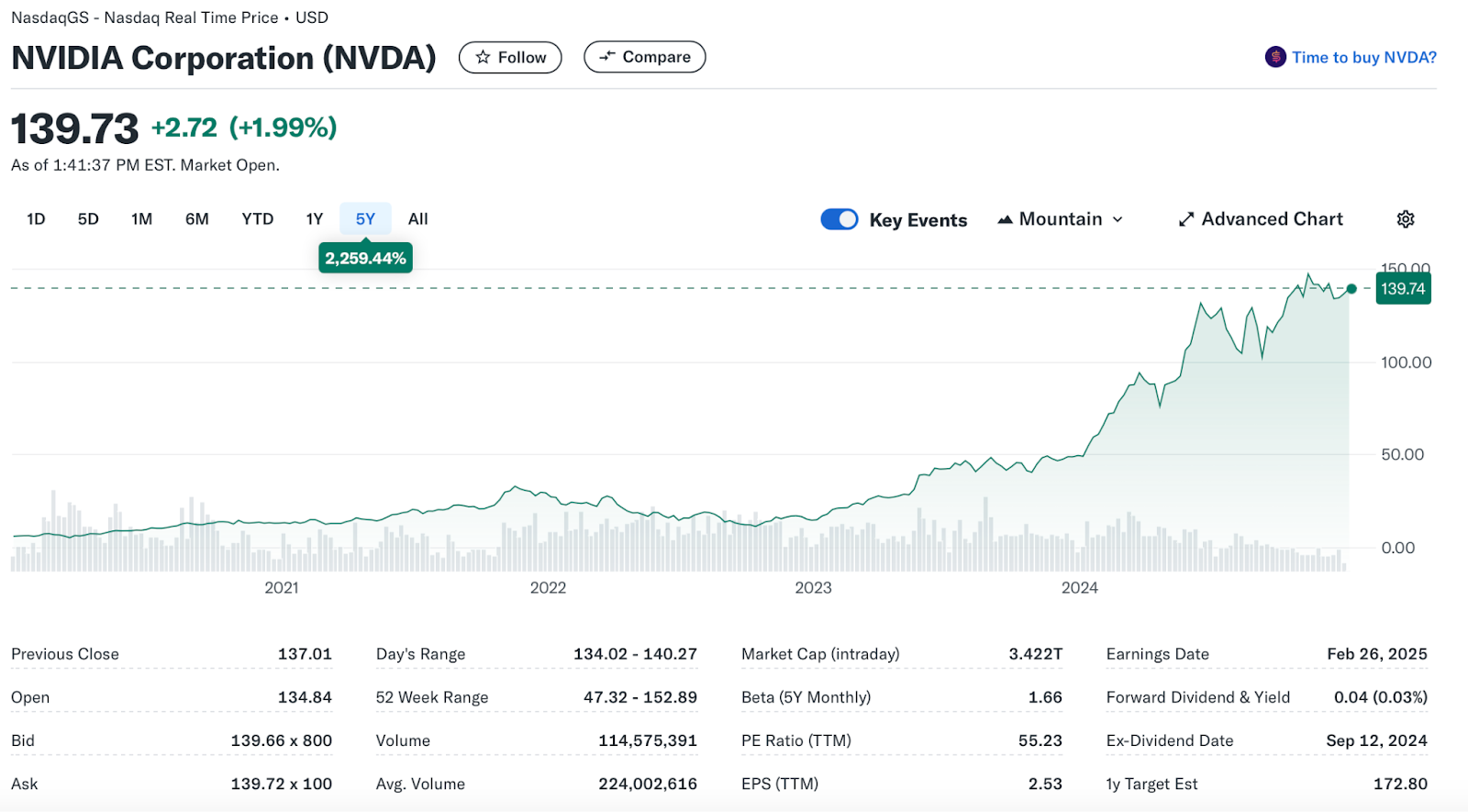
The Profiteer: If You’re Digging for Gold, You Need Shovels! (NVIDIA)
Test-time compute simply makes the models think. When we humans think, it takes a lot of energy for us to strain our brains in this way. And similar to us humans, LLMs also need energy to strain their brains for the thinking process, the compute.
“People are going to use more and more AI. Acceleration is going to be the path forward for computing. These fundamental trends, I completely believe in them.”
So far, the compute has been used primarily for two processes, inference and pre-training (as a rule of thumb, 20% of the compute is needed for training and 80% for inference). Since pre-training (scale) has reached its limits (we remember Ilyas saying: “But pre-training as we know it will unquestionably end”) and we are now achieving much better results with the help of reasoning, a large part of the compute is now needed for inference instead of training (except for TTT). Because, without a doubt, TTC is more effective than simple scale in pre-training, as Google's research has shown.
“Using our improved test-time compute scaling strategy, we then aim to understand to what extent test-time computation can effectively substitute for additional pretraining. We conduct a FLOPs-matched comparison between a smaller model with additional test-time compute and pretraining a 14x larger model. We find that on easy and intermediate questions, and even hard questions (depending on the specific conditions on the pretraining and inference workload), additional test-time compute is often preferable to scaling pretraining. This finding suggests that rather than focusing purely on scaling pretraining, in some settings it is be more effective to pretrain smaller models with less compute, and then apply test-time compute to improve model outputs.“
There is an old saying in the world of finance that the biggest profiteers of the gold rush were not the gold diggers, but the shovel sellers. Not everyone found gold, but everyone needed shovels. And in a similar way, the gold rush fever in the age of AI can be compared: not everyone has found the holy grail of AI, but everyone needs computers along the way.
In this respect, it can still be assumed that NVIDIA remains the biggest profiteer from TTC, which can be seen not least from the rapid rise in the share price. Since the demand for compute continues to be immense and cannot be met, I think there is a high chance that NVIDIA could become the most expensive company in the world by market capitalization, ahead of Microsoft and Apple.
—
Subscribe FF Daily for free to get more content from Kim Isenberg.
 | Kim IsenbergKim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society. |
Reply