- Forward Future Daily
- Posts
- 👾 The Magic of Prolonged Thinking: Test-Time Compute | Part 3
👾 The Magic of Prolonged Thinking: Test-Time Compute | Part 3
How Test-Time Compute is Revolutionizing AI with Faster Progress and Smarter Models
Kim Isenberg
January 22, 2025
Conclusion and Outlook
“Automating the generation of improved model outputs by using additional inference-time computation also provides a path towards a general self-improvement algorithm that can function with reduced human supervision.”
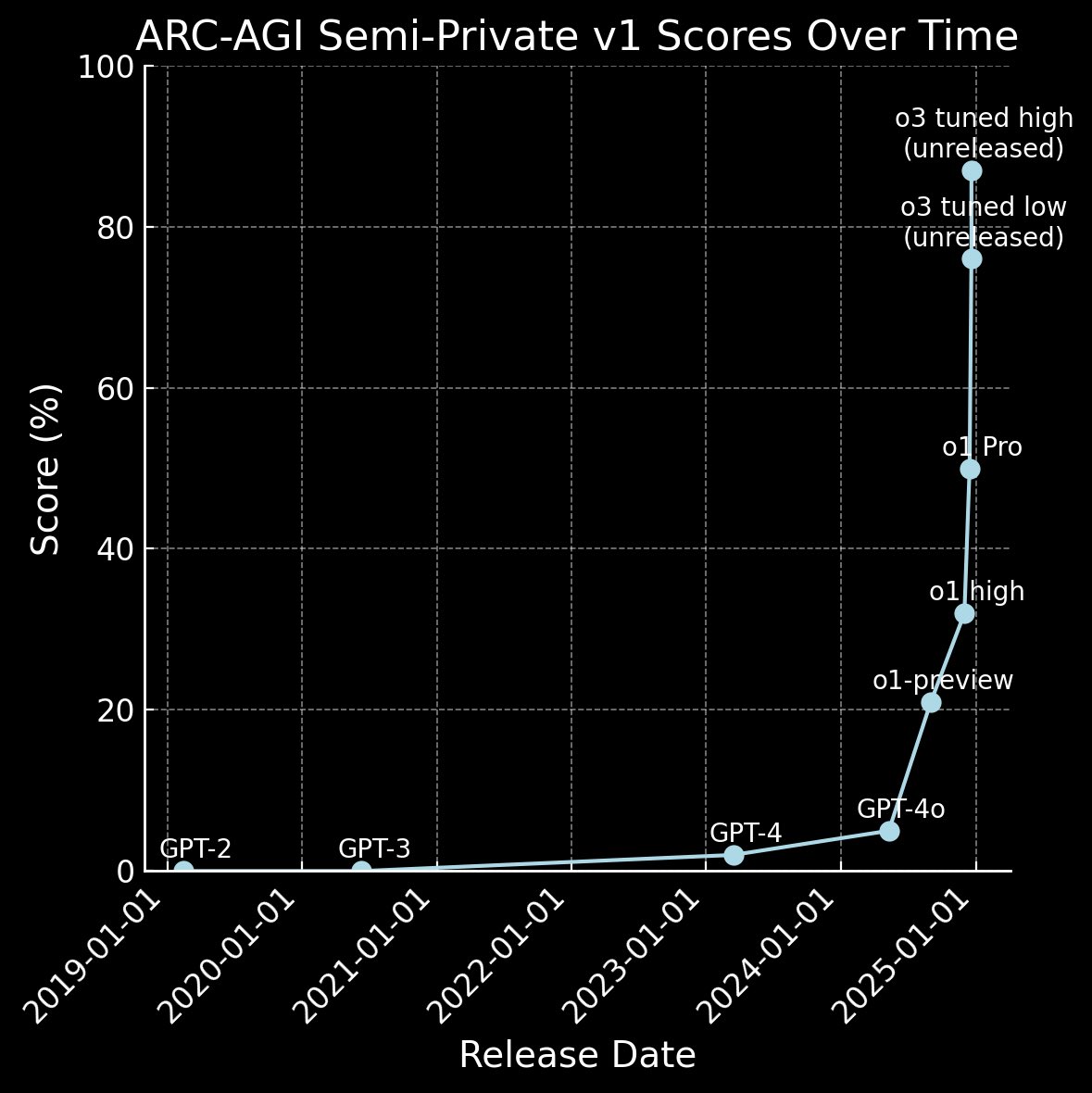
The future could be described as “sky is the limit”. The reasoning models using TTC are improving dramatically in a very short time. Within three months, OpenAI managed to saturate benchmarks that were thought to take years to saturate. The big breakthrough came recently with the solving of the ARC-AGI challenge.
The ARC-AGI Challenge is a public competition with over $1 million in prize money, aimed at developing a solution for the ARC-AGI benchmark and making it available as open source. The competition is hosted by Mike Knoop, co-founder of Zapier, and François Chollet, creator of ARC-AGI and Keras. The ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) benchmark is a unique test that measures an AI system's ability to efficiently learn new skills and apply them to unknown problems. Unlike many other benchmarks that evaluate specific skills, ARC-AGI tests a system's general intelligence and adaptability. OpenAI recently presented the new model o3, which has achieved remarkable progress in this area. The o3 model achieved an impressive 87.5% accuracy on the ARC-AGI Semi-Private Evaluation Set using extensive computing resources and longer thinking time. This value exceeds the typical human average of 85% and represents a significant milestone in the development of AI systems.
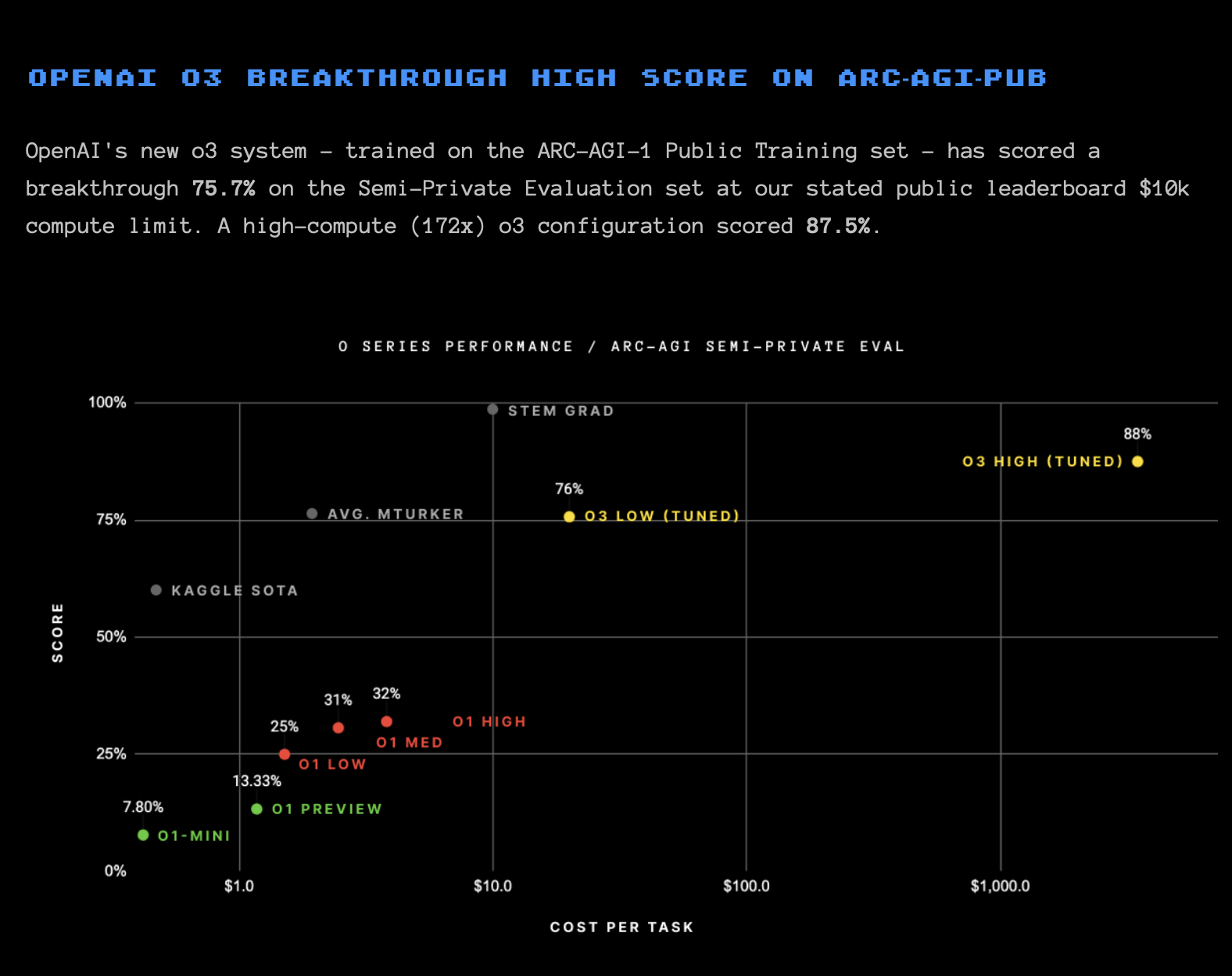
While pre-training using scale reaches its limits, it seems that reasoning using TTC, in turn, accelerates. The development from o1 to o3 took only three months, but the increase in intelligence (“reasoning”) is phenomenal.
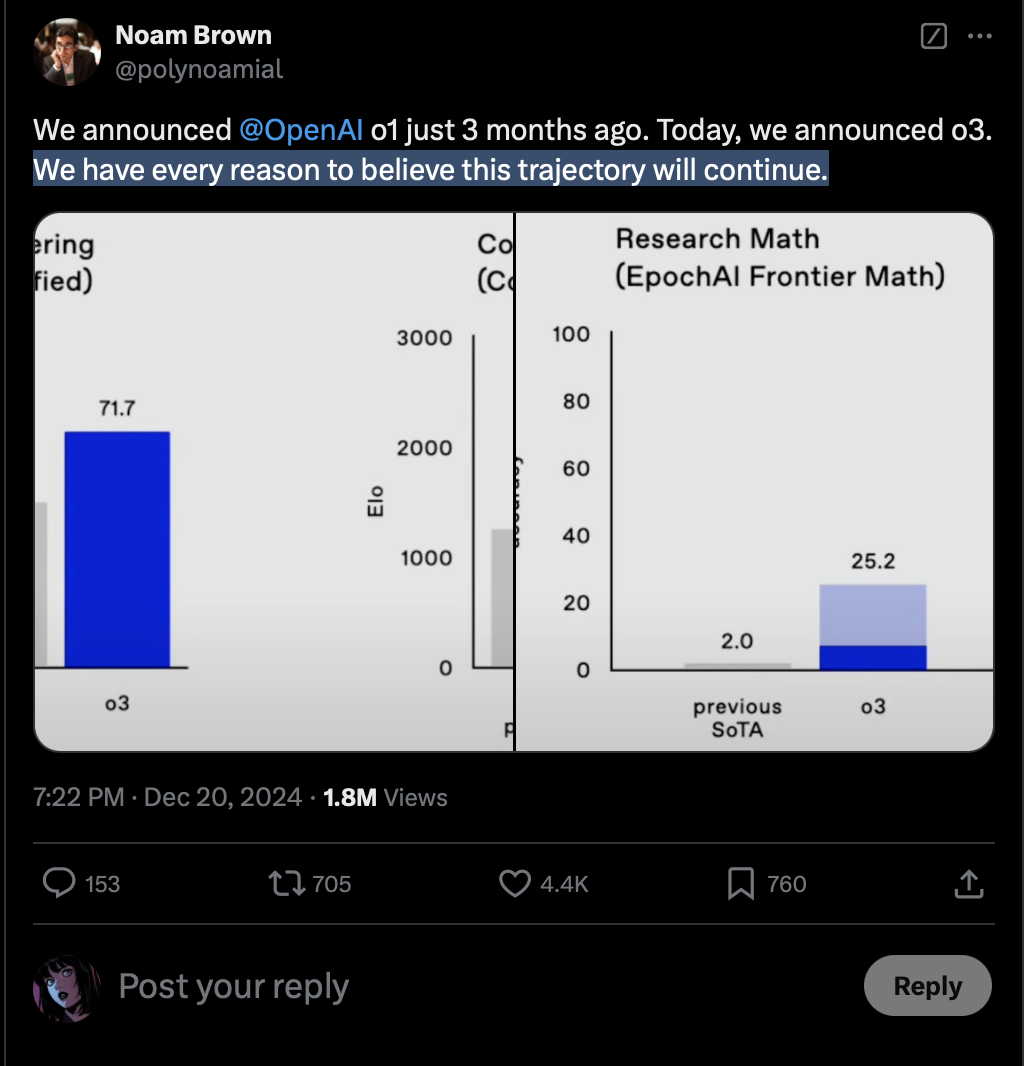
Rather, however, when you consider that there is no end in sight, as OpenAI's lead developer of their reasoning models Noam Brown recently emphasized
The question is, of course, how models with TTC can be improved. Current research shows that the limits of this approach can be further pushed by various optimization strategies. One central aspect is the refinement of the proposal distribution, in which generated answers are iteratively improved. This process enables the model to learn from previous iterations and to gradually increase its accuracy.
Another promising approach is the use of so-called verifier reward models. These models evaluate the quality of each individual solution step and thus help to guide the solution path more effectively during inference. In particular, process reward models (PRMs) provide detailed feedback on intermediate solutions and significantly improve decision-making.
In addition, adaptive inference strategies can increase the efficiency of TTC. The dynamic adaptation of computing resources based on the complexity of the input allows the model to use fewer resources for simple tasks and more for more complex problems. This flexible use of resources optimizes system performance and reduces unnecessary energy consumption.
Combining different search strategies, such as Beam Search or Diverse Verifier Tree Search (DVTS), has also proven to be extremely effective. By systematically exploring the solution space and evaluating multiple candidate solutions, language models can generate more robust and precise responses.
Finally, the further development of verifier models plays a crucial role. Robust and generalizable verifiers ensure that the quality of the generated solutions is reliably evaluated, which significantly improves the overall performance of the system.
These approaches show that test-time compute has enormous potential to further increase the efficiency and precision of AI systems. In particular, the combination of adaptive resource adjustment and improved evaluation mechanisms could help to make language models more flexible, reliable and resource-efficient.
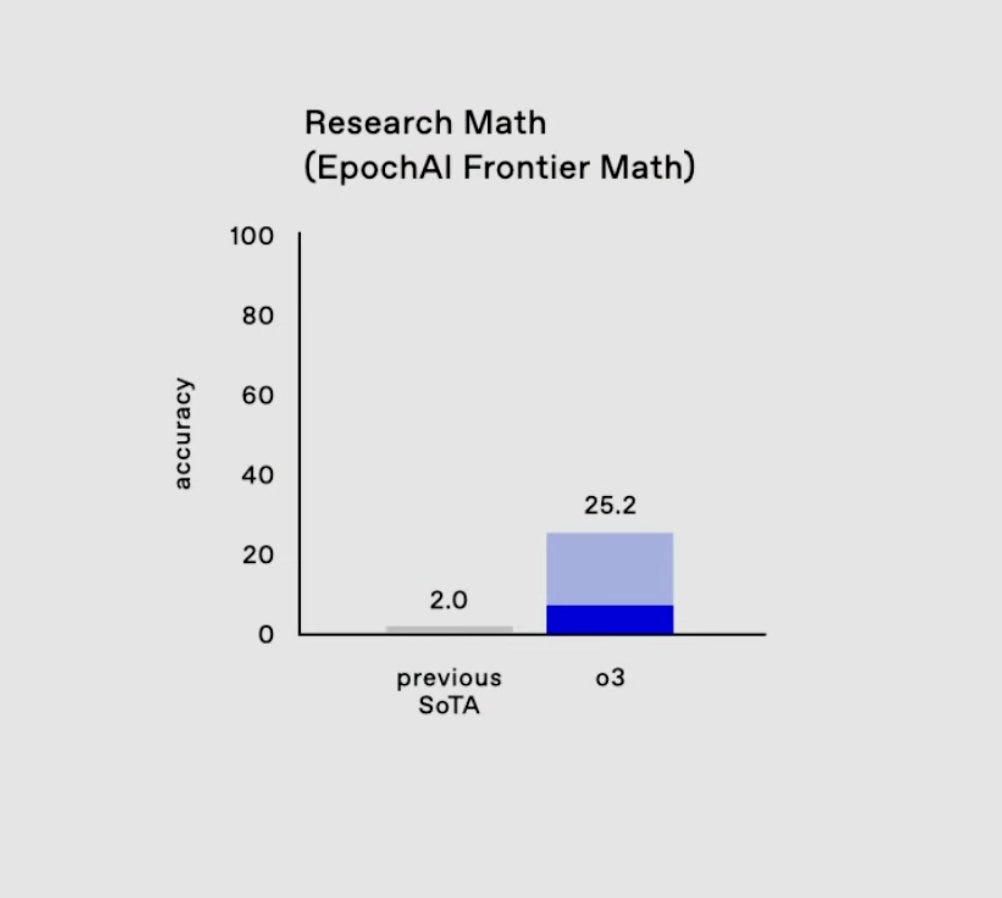
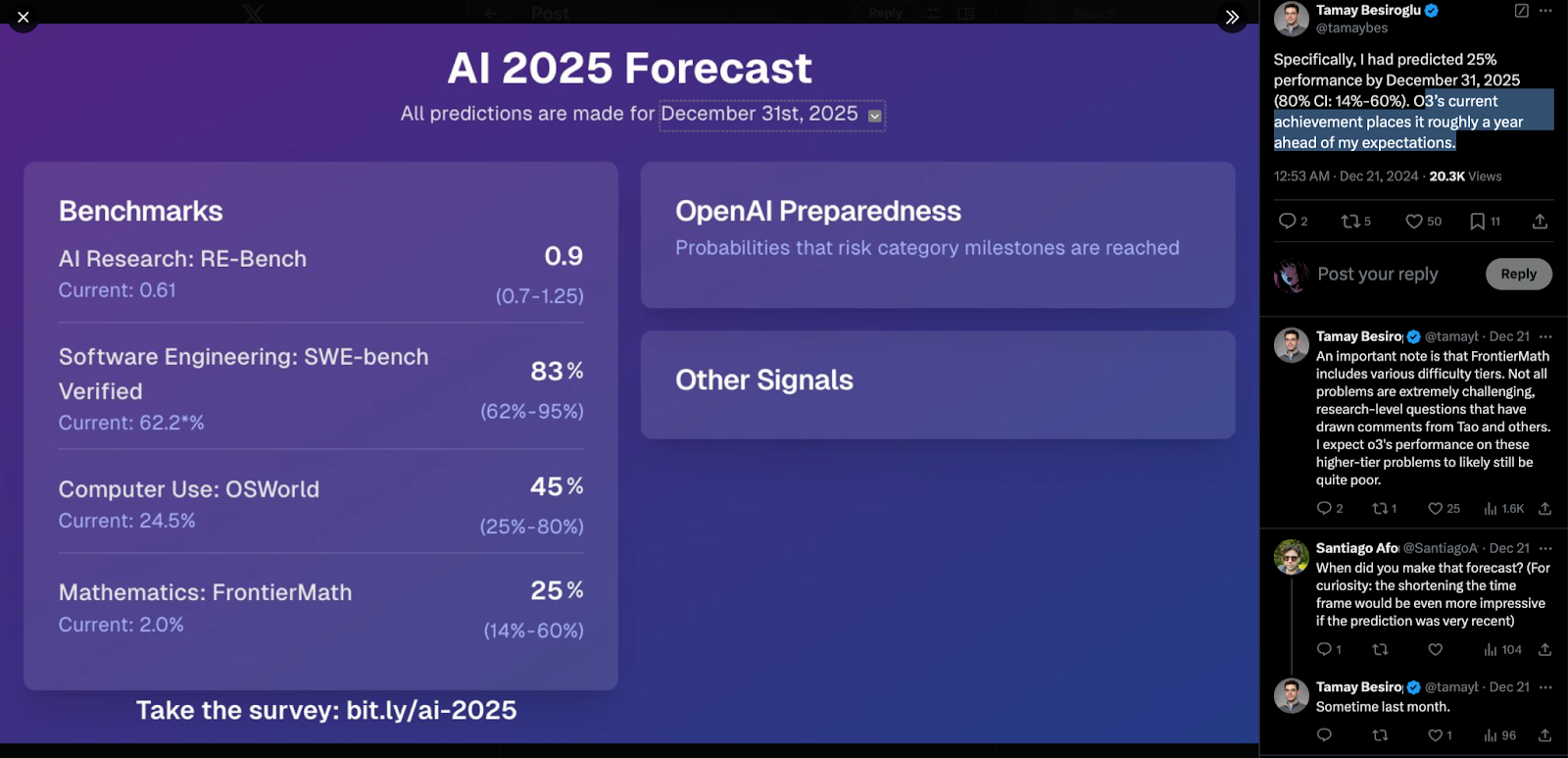
Nevertheless, it should be noted that o1 and especially the preview version of o3 have made such significant progress that even without the improvements suggested above, it is likely that further great leaps will be possible. This is because o3 has already achieved 25% of the results of the extremely difficult benchmark MathFrontier, which the developer had not expected until a year later.
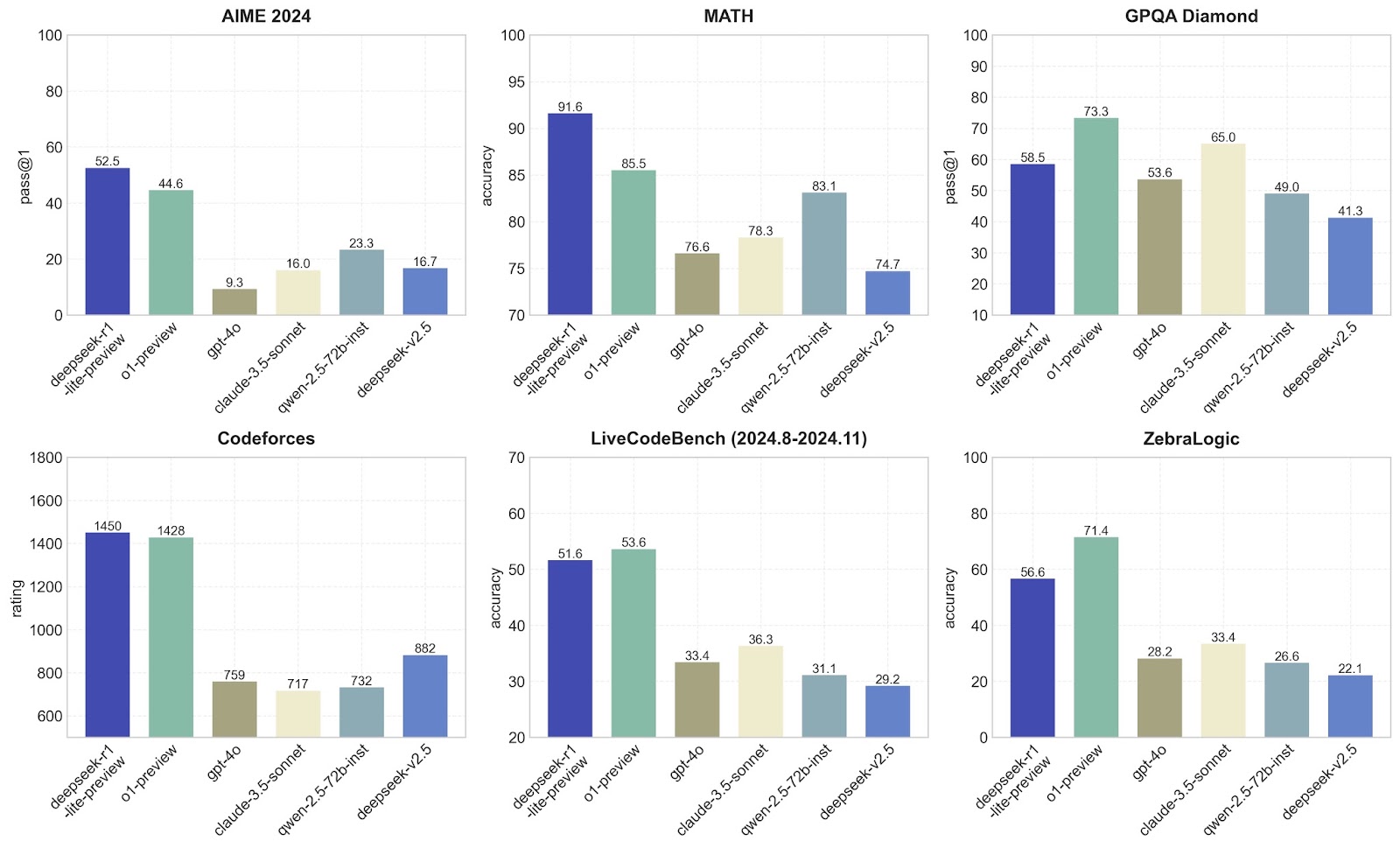
But now OpenAI is no longer the only company developing excellent reasoning models. Google recently released its first own reasoning model, Gemini 2.0 Flash thinking, and DeepSeek has released r1, a Chinese alternative that is almost as good as its competitors.
In summary, it can be said that although we reached a limit in pre-training, with TTT and especially TTC we have found a new way to significantly improve the models and do reasoning. If you believe the researchers, there is no end in sight to the development and significant performance increase. On the contrary, ever tougher benchmarks are needed to measure future performance.
NVIDIA is likely to continue to be the biggest beneficiary, as it can hardly meet the demand for computing power. And since, in addition to the big players such as OpenAI, Anthropic, Google and Meta, Chinese companies are now also increasingly involved (although they are subject to major compute embargoes), both the demand for compute and the increase in performance are likely to continue significantly until 2025. And o3 has given us a taste of the short time frame in which significant performance leaps are possible. This sense of wonder will probably stay with us for a long time.
—
Subscribe FF Daily for free to get more content from Kim Isenberg.
 | Kim IsenbergKim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society. |
|

Reply