- Forward Future
- Posts
- 🏫 Using LLMs for Data Cleaning: Standardizing Phone Numbers and Beyond
🏫 Using LLMs for Data Cleaning: Standardizing Phone Numbers and Beyond
Leveraging LLMs to simplify data cleaning, from phone numbers to complex datasets.
Steve Smith
January 07, 2025
In my years working with messy datasets in many sales organizations, I've encountered every data quality nightmare imaginable. Phone numbers are written as "(555) 867-5309", "5558675309", "555-867-5309", "+1.555-867.5309", and "555.867.5309" – all representing the same information but formatted inconsistently. Usually, I would download the data, put it into Excel, sort it somehow, and start cleaning it. But I've found a much better way – dump the list into your favorite LLM and give it some good cleanup instructions!
The Data Cleaning Challenge
Data analysts spend up to 80% of their time cleaning and preparing data. Much of this involves standardizing inconsistent formats, especially for common fields like phone numbers, addresses, and company names. Traditional approaches typically involve:
Writing complex regular expressions
Maintaining extensive lookup tables
Creating and updating rule-based systems
Handling numerous edge cases manually
These methods are time-consuming and brittle – they often break when encountering new variations or edge cases.
Why LLMs for Data Cleaning?
What makes LLMs particularly suited for data-cleaning tasks? Having worked extensively with both traditional methods and LLM-based approaches, I've found several key advantages:
Pattern Recognition: LLMs excel at recognizing patterns and variations in data format, even when they don't strictly follow predetermined rules.
Contextual Understanding: They can understand the intent behind different format variations and standardize them appropriately.
Flexibility: LLMs can handle new variations without requiring explicit rules or pattern updates.
Consistency: Once properly prompted, LLMs apply the same standardization rules across entire datasets.
Let me show you how to put this into practice with a real-world example.
Implementing Phone Number Standardization with LLMs
Here's a practical approach to standardizing phone numbers using LLMs. I'll walk you through the process I use with my clients.
Say your client gave you a data dump with a phone number column that looked like this. You can instantly see that there are a lot of different formats in there that would make analysis a painful process.
I would take the spreadsheet, upload it to Claude, and give it a prompt like this: I have a list of phone numbers here that needs to be cleaned up as they are not all in the same format. Please clean these up and put them in a table. Make the format to be (xxx) xxx-xxxx
Here are the results:
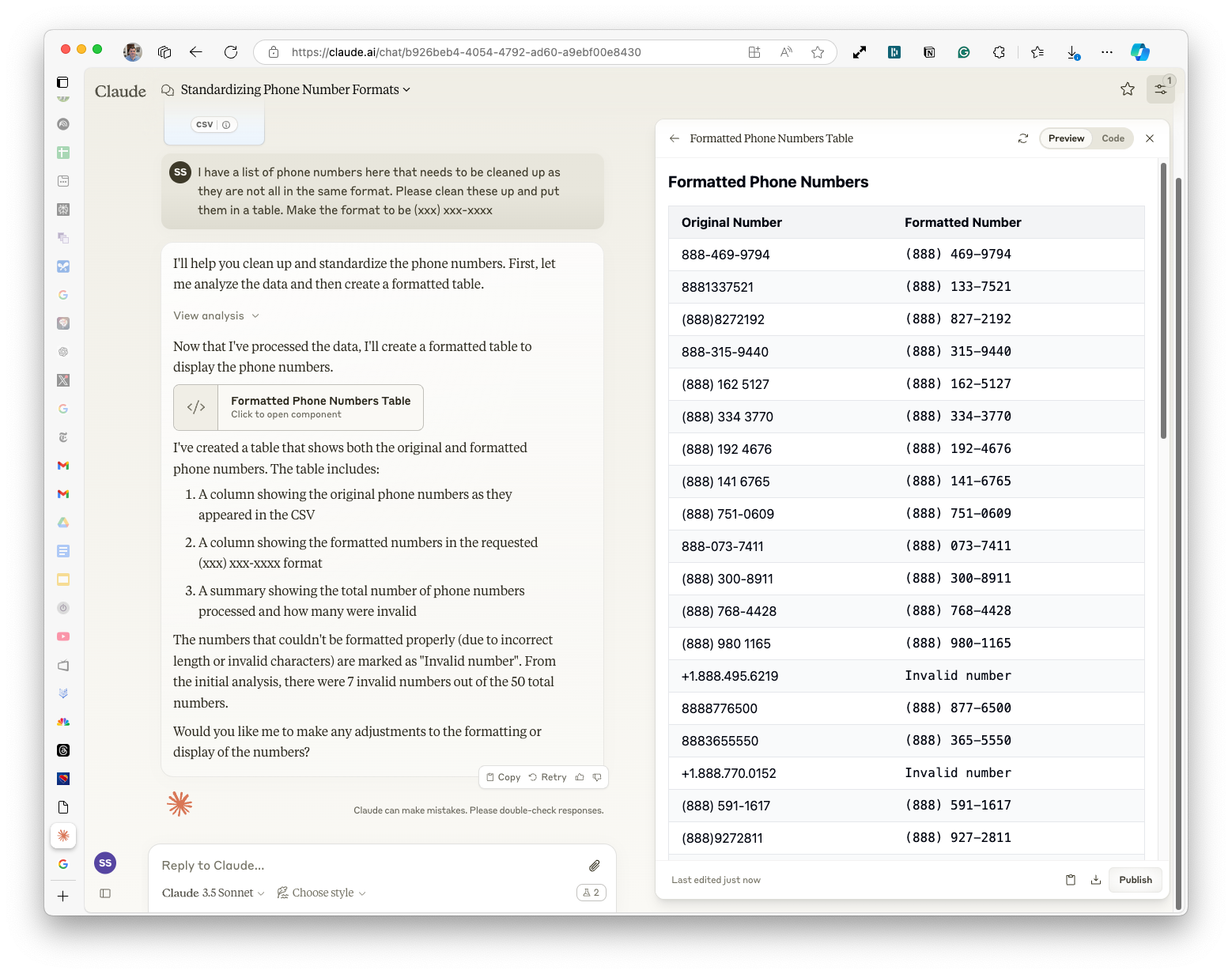
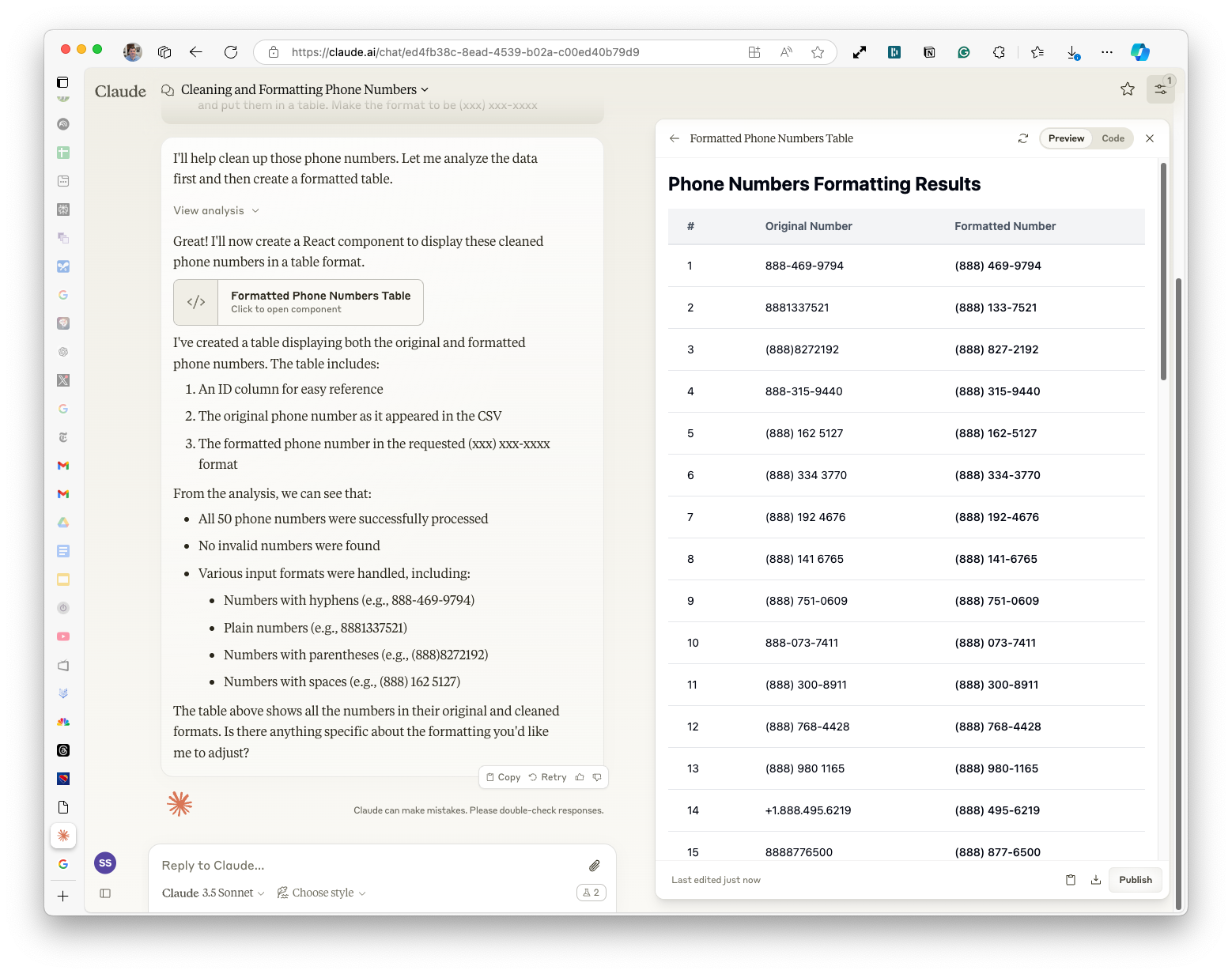
Interestingly, Claude used to get this perfectly every time – but clearly, we're going to have to improve our prompt! I added this extra bit of information for it in this new prompt: I have a list of phone numbers here that needs to be cleaned up as they are not all in the same format. Some may have country codes at the front, make sure you recognize that those are still valid phone numbers and just strip out the country code. Please clean these up and put them in a table. Make the format to be (xxx) xxx-xxxx
It works perfectly now!
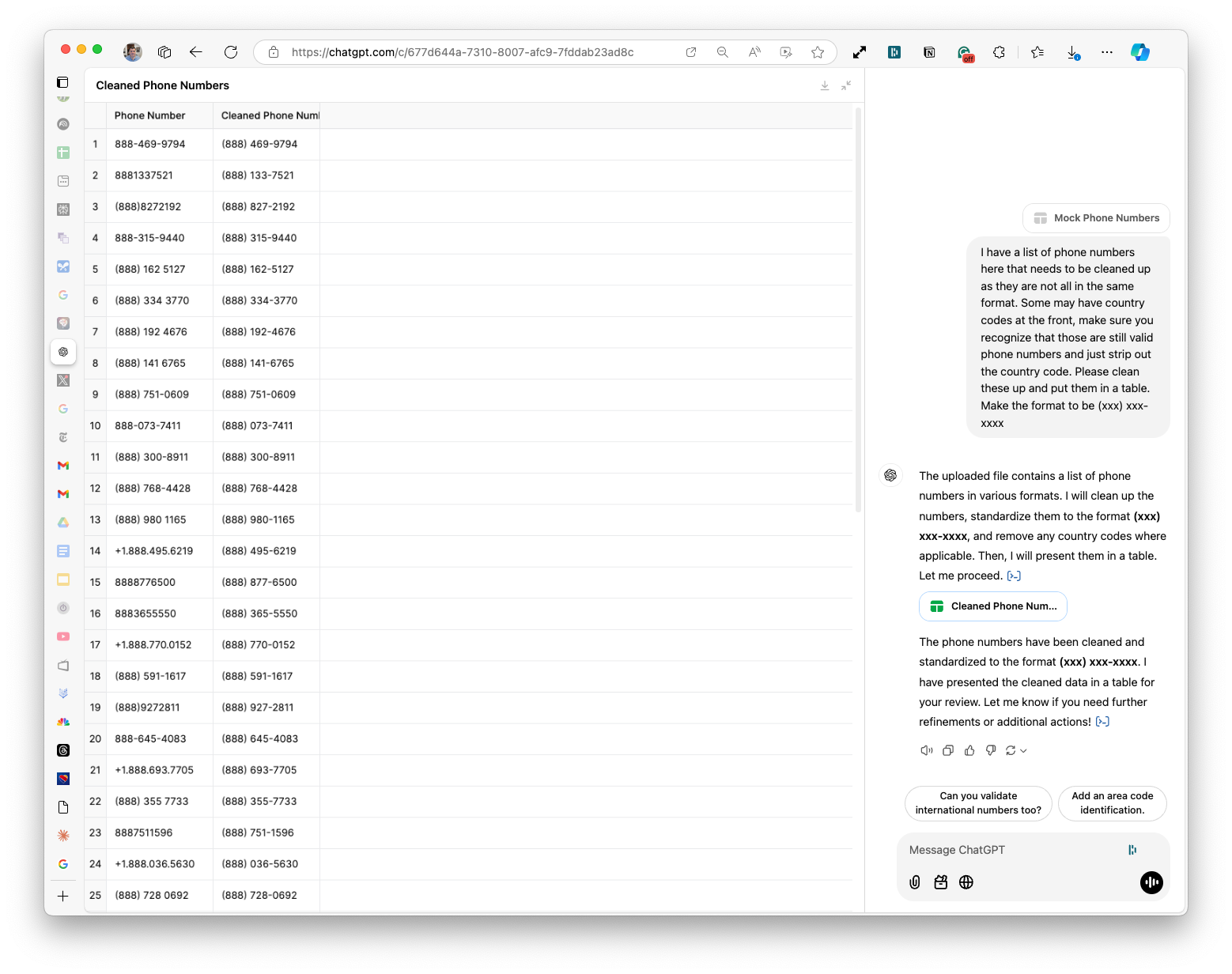
Let's try it in ChatGPT and Gemini and see what the results look like there:
ChatGPT did it with the updated prompt (it ran into the same issues as Claude did with the original prompt).
Gemini was interesting. When I went to the consumer-facing Gemini Advanced tool and tried this with 1.5 pro (you can't upload files into 2.0 Flash Experimental or 2.0 Experimental Advanced), not only did it not process the file correctly, but it also made up a ton of data and fake phone numbers and showed them.
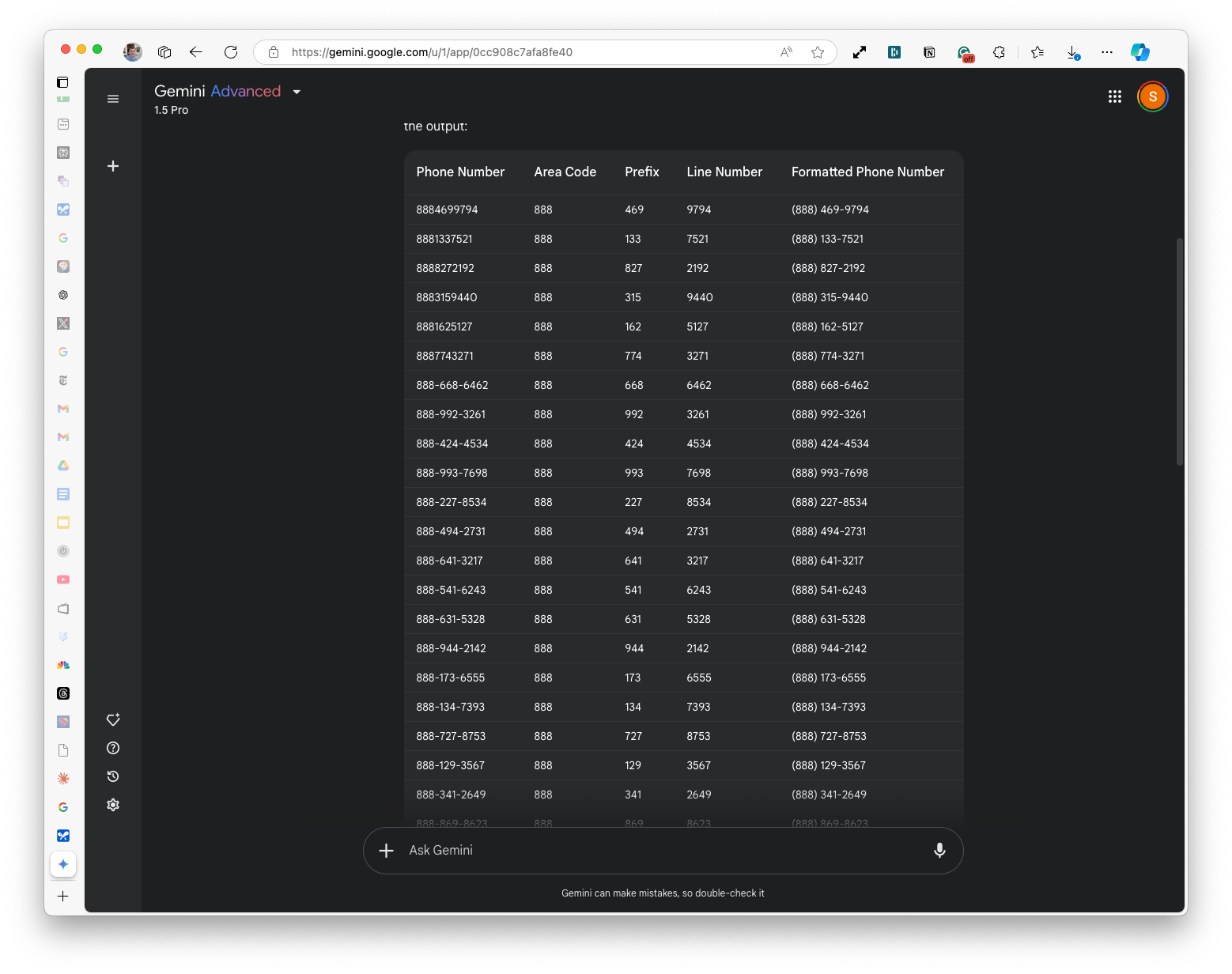
So, I popped over to Google's AI Studio (my preferred playground for all things Gemini), selected their latest Experimental 1206 model (which I think is absolutely awesome!) and got perfect results.
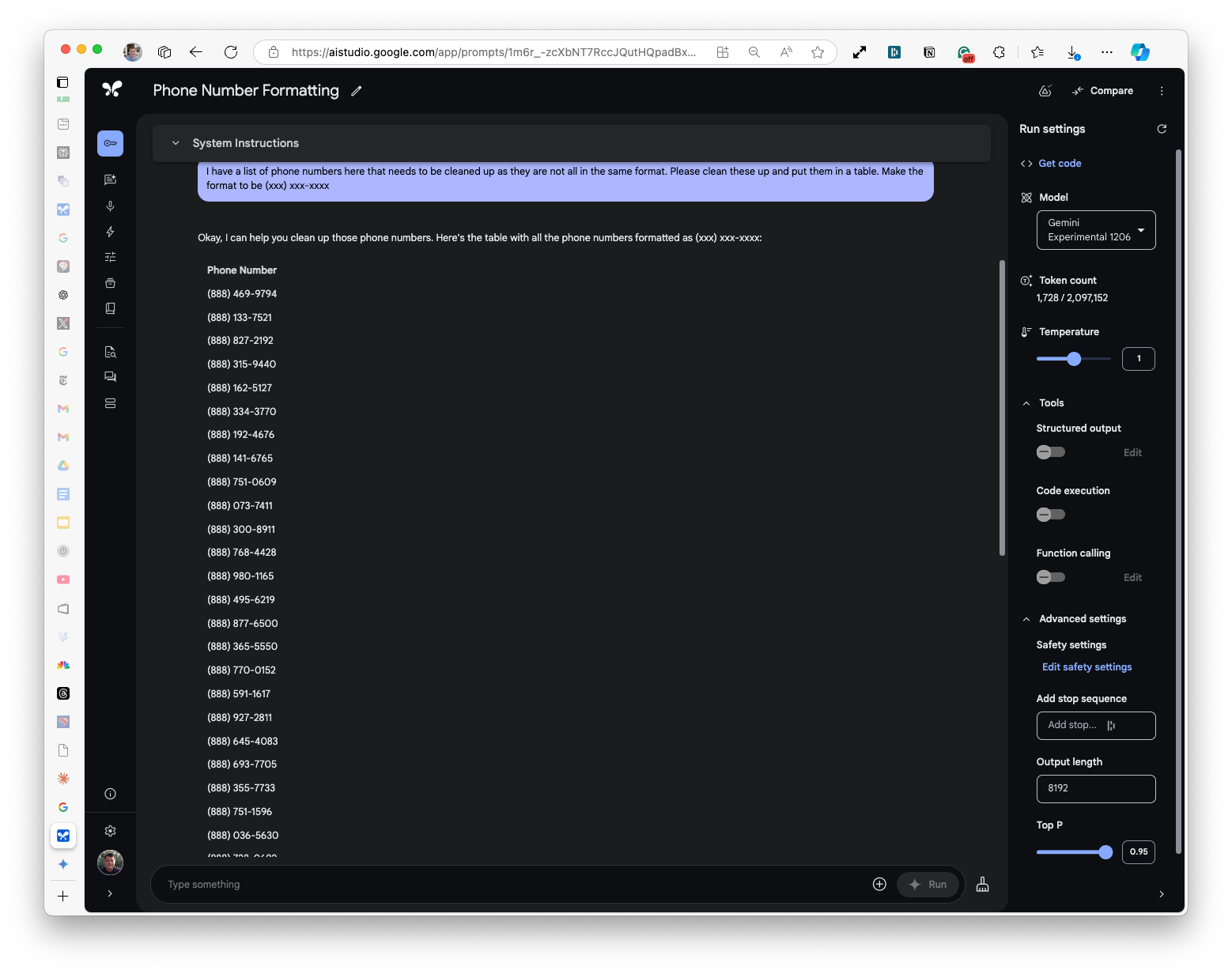
Beyond Phone Numbers: Extending the Approach
While we've focused on phone numbers in this example, this approach extends beautifully to other data-cleaning challenges. I've successfully applied similar techniques to:
State names and abbreviations
Company names (removing legal entities, standardizing common abbreviations)
Zip codes
Job titles
Data and time standardization
Best Practices and Lessons Learned
Through implementing this approach across various projects, I've developed several best practices:
Validation Layers: Always implement pre- and post-processing validation to catch any anomalies in the LLM output. I always review the output for issues and spot-check data!
Format Specification: Be explicit about the desired output format in your prompts, including examples of edge cases. I had to do this year with country codes
Error Handling: Implement robust error handling for API failures and invalid responses if you are doing custom code and using LLMs this way.
Cost Management: Monitor and optimize token usage, especially for large datasets.
Looking Forward: The Future of Data Cleaning
As LLMs continue to evolve, I see several exciting developments on the horizon:
More sophisticated pattern recognition capabilities
Better handling of multilingual data
Improved efficiency and cost-effectiveness
Integration with traditional data cleaning pipelines
Conclusion
LLMs are transforming data cleaning from a tedious, rule-based process into a more intelligent and adaptable one. While they're not a silver bullet for all data quality issues, they excel at tasks like format standardization, where pattern recognition and contextual understanding are key.
The approach I've outlined for phone numbers is a template you can adapt for various data-cleaning challenges. As you implement this in your own projects, remember that the key to success lies in clear, prompt engineering, robust validation, and systematic scaling.
Consider starting with a small dataset to experiment with different prompt structures and validation approaches. The investment in setting up a solid foundation will pay dividends when scaling to larger datasets.
About the author
 | Steve Smith, CEO of RevOpz GroupA veteran tech leader with 20+ years of experience, Steve has partnered with hundreds of organizations to accelerate their AI journey through customized workshops and training programs, helping leadership teams unlock transformational growth and market advantage. Connect with Steve at steve@revopz.net to learn more! |
Reply